vLLM私有化部署和运行DeepSeek模型
前言
25年春节前后,随着DeepSeek的爆火,思维链、蒸馏等名词被大家所熟知。再加上DS模型开源可商用,所以很多大厂、企业都纷纷进行私有化部署。本篇文章就基于阿里云GPU来实战部署DS模型,由于是个人体验,使用千问系列DS蒸馏模型:DeepSeek-R1-Distill-Qwen-1.5B。
本地部署
环境准备
1、评估模型所需的配置

部署 DeepSeek-R1-Distill-Qwen-1.5B,选择c4m30 GPU24G即可,系统盘50G(测试发现需要50+G)。
2、选购GPU实例
选择推荐GPU版本:ecs.gn7i-c8g1.2xlarge、8 vCPU 30 GiB、1 * NVIDIA A10、1 * 24 GB
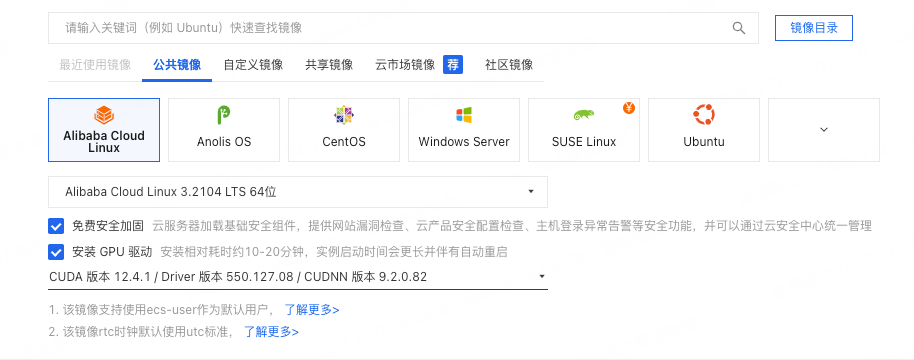
勾选安装GPU驱动,更方便
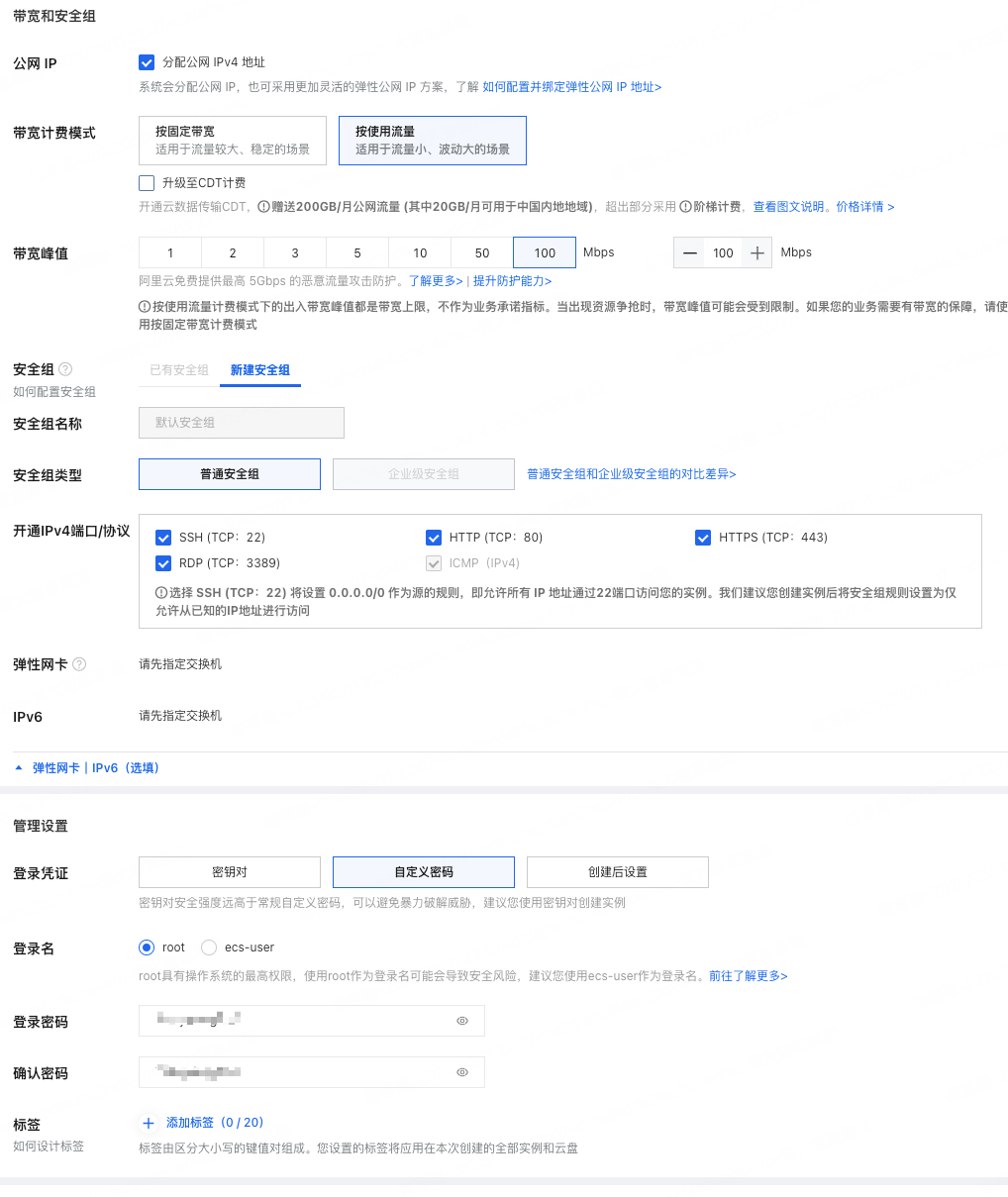
按流量计费:配置到点释放资源
带宽峰值:100M,加速模型下载
登陆凭证:使用自定义密码
安全组:开放22和8080(此处没有8080,可以实例创建后,手动添加)
选择购买时长,完成订单支付,然后等待实例分配即可。
3、安装Docker环境
依次执行如下命令:
#添加Docker软件包源
sudo wget -O /etc/yum.repos.d/docker-ce.repo http://mirrors.cloud.aliyuncs.com/docker-ce/linux/centos/docker-ce.repo
sudo sed -i 's|https://mirrors.aliyun.com|http://mirrors.cloud.aliyuncs.com|g' /etc/yum.repos.d/docker-ce.repo
#Alibaba Cloud Linux3专用的dnf源兼容插件
sudo dnf -y install dnf-plugin-releasever-adapter --repo alinux3-plus
#安装Docker社区版本,容器运行时containerd.io,以及Docker构建和Compose插件
sudo dnf -y install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
#启动Docker
sudo systemctl start docker
#设置Docker守护进程在系统启动时自动启动
sudo systemctl enable docker
通过输入 docker -v,验证docker是否安装成功。
修改 /etc/docker/daemon.json 配置镜像源,并重启docker服务:
{
"registry-mirrors": ["https://kkk3bt3i.mirror.aliyuncs.com"]
}
4、安装NVIDIA容器工具包
执行如下命令:
#配置生产存储库(如下两行是一条命令,结尾 \ 换行)
curl -s -L https://nvidia.github.io/libnvidia-container/stable/rpm/nvidia-container-toolkit.repo | \
sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repo
#安装 NVIDIA Container Toolkit 软件包
sudo yum install -y nvidia-container-toolkit
#重启docker
sudo systemctl restart docker
部署并运行DeepSeek模型
1、登陆服务器
ssh root@ip
输入密码即可。
2、下载推理镜像
sudo docker pull egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/vllm:0.6.4.post1-pytorch2.5.1-cuda12.4-ubuntu22.04
egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/vllm:0.6.4.post1-pytorch2.5.1-cuda12.4-ubuntu22.04是镜像名称。
egs-registry.cn-hangzhou.cr.aliyuncs.com 表示镜像的仓库地址,阿里云
egs/vllm:命名空间 + 镜像名称,vllm表示一个基于 vLLM 框架的镜像
0.6.4.post1-pytorch2.5.1-cuda12.4-ubuntu22.04:0.6.4.post1表示镜像版本,其它表示镜像标签
vLLM 是一个高性能、内存高效的推理和服务引擎,专为大型语言模型(LLMs)设计,旨在提供快速、低成本且易于使用的 LLM 推理和部署解决方案。github地址:https://github.com/vllm-project/vllm
3、下载模型,从阿里云魔塔社区 Modelscope 下载
# 定义要下载的模型名称。MODEL_NAME需要访问Modelscope选择模型,在模型详情页获取名称,脚本以DeepSeek-R1-Distill-Qwen-1.5B为例
MODEL_NAME="DeepSeek-R1-Distill-Qwen-1.5B"
# 设置本地存储路径。确保该路径有足够的空间来存放模型文件(建议预留模型大小的1.5倍空间),此处以/mnt/1.5B为例
LOCAL_SAVE_PATH="/mnt/1.5B"
# 如果/mnt/1.5B目录不存在,则创建它
sudo mkdir -p ${LOCAL_SAVE_PATH}
# 确保当前用户对该目录有写权限,根据实际情况调整权限
sudo chmod ugo+rw ${LOCAL_SAVE_PATH}
# 启动下载,下载完成后自动销毁(下面是一条命令)
sudo docker run -d -t --network=host --rm --name download \
-v ${LOCAL_SAVE_PATH}:/data \
egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/vllm:0.6.4.post1-pytorch2.5.1-cuda12.4-ubuntu22.04 \
/bin/bash -c "git-lfs clone https://www.modelscope.cn/models/deepseek-ai/${MODEL_NAME}.git /data"
命令行输入:变量=“” 表示会话级别的变量
可以通过命令查看下载进度: sudo docker logs -f download
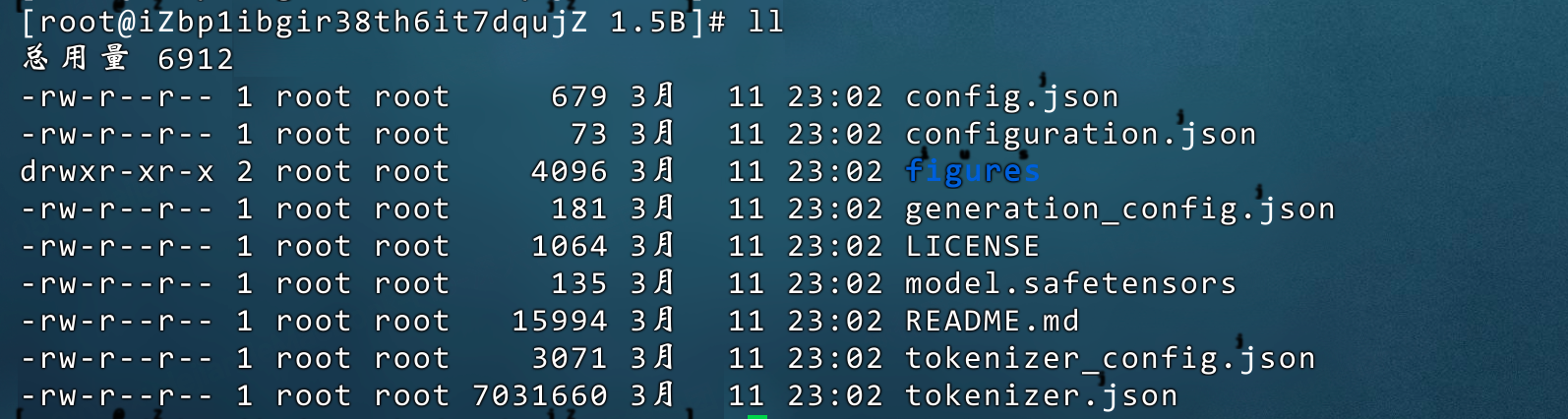
下载成功后模型目录:
4、启动模型推理服务
执行如下命令:
# 定义使用的GPU数量。这取决于实例上可用的GPU数量,可以通过nvidia-smi -L命令查询
# 这里假设使用1个GPU
TENSOR_PARALLEL_SIZE="1"
# 启动Docker容器并运行服务(下面是一条命令)
sudo docker run -d -t --network=host --gpus all \
--privileged \
--ipc=host \
--name ${MODEL_NAME} \
-v ${LOCAL_SAVE_PATH}:/data \
egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/vllm:0.6.4.post1-pytorch2.5.1-cuda12.4-ubuntu22.04 \
/bin/bash -c "vllm serve /data \
--port ${PORT} \
--served-model-name ${MODEL_NAME} \
--tensor-parallel-size ${TENSOR_PARALLEL_SIZE} \
--max-model-len=16384 \
--enforce-eager \
--dtype=half"
命令行执行 nvidia-smi -L 如果返回 GPU0,表示只有1个GPU可用, TENSOR_PARALLEL_SIZE设置成1即可。
最后的/bin/bash -c 表示,容器启动后,在容器内部之心 -c之后的脚本。
vllm serve 是 vLLM 提供的一个命令,用于启动一个 vLLM 服务器,以便部署和运行大型语言模型(LLMs)。具体来说,它会在指定的端口上启动一个 API 服务,允许用户通过 HTTP 请求与模型进行交互,生成文本或执行其他推理任务。
– /data:指定模型文件的路径或 Hugging Face 模型名称。
– --port ${PORT}:设置服务器监听的端口号。
– --served-model-name ${MODEL_NAME}:指定要部署的模型名称。
– --tensor-parallel-size ${TENSOR_PARALLEL_SIZE}:设置 Tensor 并行的 GPU 数量,用于多 GPU 分布式推理。
– --max-model-len=16384:设置模型支持的最大上下文长度(token 数量)。
– --enforce-eager:强制使用 Eager 模式执行推理,通常用于调试或特殊场景。
– --dtype=half:指定模型的计算数据类型为 float16,以减少显存占用并提高推理速度。
检查服务是否启动正常:sudo docker logs ${MODEL_NAME}
启动 Open WebUI 对话
1、拉取python3镜像
sudo docker pull alibaba-cloud-linux-3-registry.cn-hangzhou.cr.aliyuncs.com/alinux3/python:3.11.1
2、启动Open WebUI服务
执行如下命令:
#设置模型服务地址
OPENAI_API_BASE_URL=http://127.0.0.1:30000/v1
# 创建数据目录,确保数据目录存在并位于/mnt下
sudo mkdir -p /mnt/open-webui-data
#启动open-webui服务(一条命令)
sudo docker run -d -t --network=host --name open-webui \
-e ENABLE_OLLAMA_API=False \
-e OPENAI_API_BASE_URL=${OPENAI_API_BASE_URL} \
-e DATA_DIR=/mnt/open-webui-data \
-e HF_HUB_OFFLINE=1 \
-v /mnt/open-webui-data:/mnt/open-webui-data \
alibaba-cloud-linux-3-registry.cn-hangzhou.cr.aliyuncs.com/alinux3/python:3.11.1 \
/bin/bash -c "pip config set global.index-url http://mirrors.cloud.aliyuncs.com/pypi/simple/ && \
pip config set install.trusted-host mirrors.cloud.aliyuncs.com && \
pip install --upgrade pip && \
pip install open-webui==0.5.10 && \
mkdir -p /usr/local/lib/python3.11/site-packages/google/colab && \
open-webui serve"
查看日志,启动成功,8080端口暴露服务。
3、通过 访问 http://公网ip:8080 进行访问
首次访问注册:
选择模型并进行问答:
问题记录
1、启动模型推理服务报错
docker: Error response from daemon: could not select device driver “” with capabilities: [[gpu]].
分析:错误表明 Docker 无法识别或使用 GPU 设备,通常是因为缺少 NVIDIA 容器工具包(NVIDIA Container Toolkit)或未正确配置
解决:运行以下命令,确认 NVIDIA 容器工具包已正确安装:
nvidia-container-toolkit --version
如果显示版本号,说明安装成功;否则进行安装。
最后,重启docker好了,sudo systemctl restart docker
2、启动模型推理服务报错
docker: Error response from daemon: Conflict. The container name “/DeepSeek-R1-Distill-Qwen-1.5B” is already in use by container “41ec805f95b44532185646c29e24eb9ede986a3ac9409d728556371c0d827440”. You have to remove (or rename) that container to be able to reuse that name.
分析:是在 重新执行 docker run … 时报错,容器已经存在
解决:删除镜像 sudo docker rm -f 41ec805f95b44532185646c29e24eb9ede986a3ac9409d728556371c0d827440
重新执行命令 docker run。
或者 docker ps -a 查看容器名,docker start 容器名启动
3、启动Open WebUI报错
ERROR: Could not install packages due to an OSError: [Errno 28] No space left on device
分析:磁盘不足了

解决:扩容系统盘

总结
通过GPU进行私有化部署DS蒸馏版1.5B模型(150亿参数),还可以选择其它不同参数的开源模型;另外针对垂直领域,可以在私有化部署的基础上,进行微调(SFT),来进一步提升模型的性能。