ElasticSearch是如何实现近实时搜索的?
前言
我们都知道ElasticSearch(ES)是近实时搜索引擎,它不像关系型数据库一样,通过事务和隔离性来控制数据的可见。ES主要用于大数据量和复杂场景的检索或聚合能力,近实时也是为了提高索引和检索的性能,那么它是如何做到的呢?
我们先来看几个概念。
概念
Lucene
ES底层就是使用了Apache Lucene这个Java搜索库,提供了基础的索引和搜索能力,lucene使用倒排索引进行词条的检索。
ES和Lucene的关系,如下:
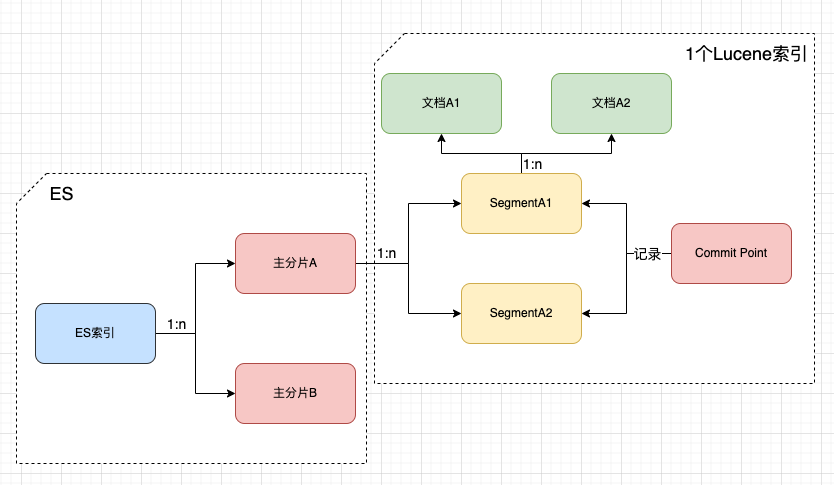
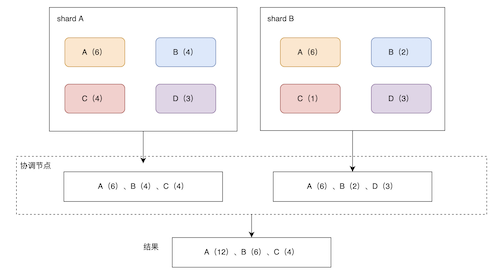
一个ES索引文档会被Hash到不同的主分片上,一个分片就对应着一个Lucene索引。
Lucene索引包括多个Segment段,每个Segment段又包括多个Document文档信息。
记录段信息的叫Commit Point提交点(记录索引的状态、可以理解成一种快照)。
关于倒排索引:
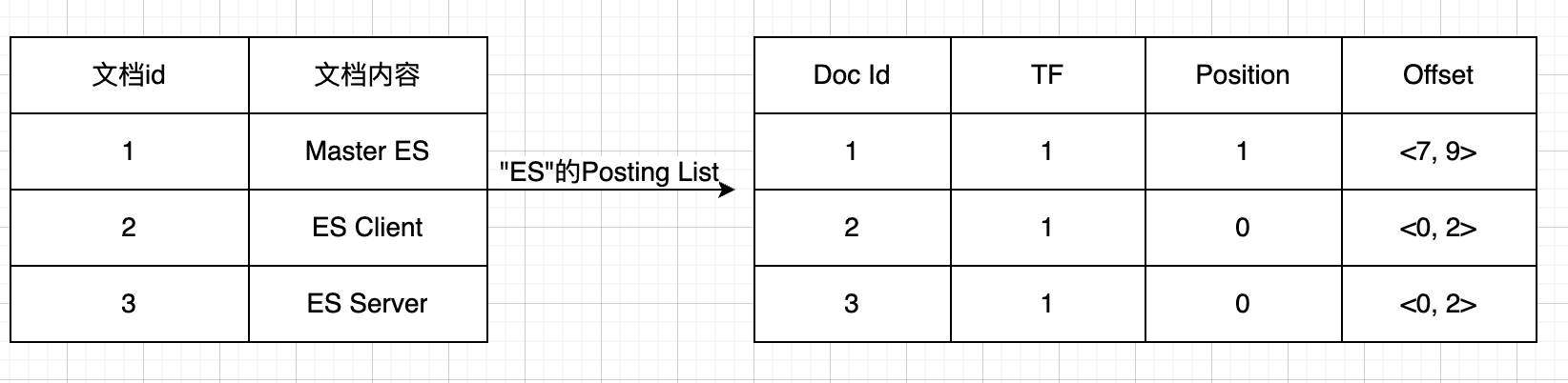
倒排索引包括了两部分,单词词典、倒排列表
单词词典:记录了所有文档的单词
倒排列表:对应的文档信息,包括文档Id、词频(TF)、位置(Position)、偏移(Offset)。
倒排索引有个特点:不可变性
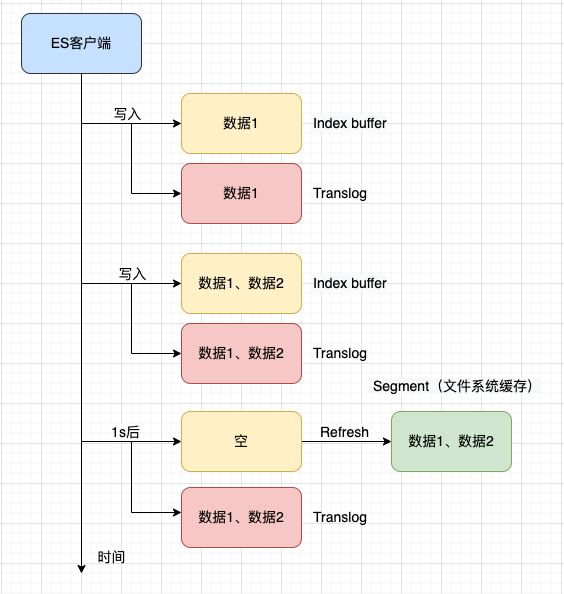
Refresh
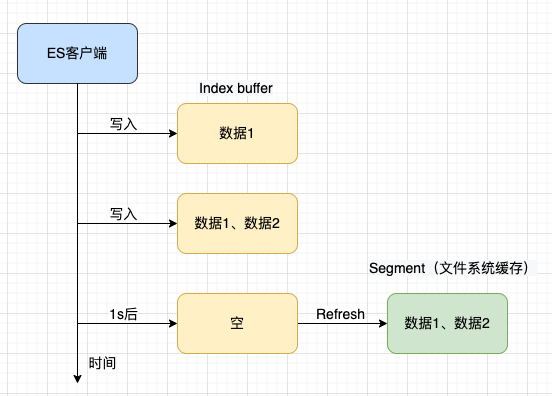
ES在创建文档时,会将数据先保存到索引内存Index buffer中,对于Index buffer中的文档数据,只能写入不能读取。
Refresh动作是指将Index buffer中的数据写入Segment的过程,写入的区域是文件缓存系统(操作系统的内存),而不是磁盘,它是一个比较轻量级的动作。写磁盘需要进行Fsync,同时会创建一个Lucene commit point。
默认情况1s刷新一次或者Index buffer被写满的时候(Index buffer内存的默认值大小是JVM的10%),可以通过index.refresh_interval配置刷新时间。
一旦数据被写入Segment便可以被搜索到,所以索引文档默认延迟1s被搜索到的原因,即ES是近实时的。
但是因为是先写在内存Index buffer中,就会出现可能因为ES实例重启数据丢失情况,便引入了事务日志Transction log。
ES提供了手动Refresh Api:
POST <target>/_refresh
Api传送门>
Translog
Lucene的Segment只有在提交后才会被存储到磁盘,这是个耗时的操作。所以引入了Transction log,又叫Translog。
Translog是一个事务日志文件,记录着ES提交后的新数据,每个分片都对应着一个Translog,通过顺序写的方式进行追加(WAL:数据库常用手段),这种方式是相当快的。所以在索引数据到Index buffer的时候,会同时写入到Translog中(文件缓存系统)。文件缓存系统的数据只有在Fsync(系统文件同步)后,才会进行落盘,数据才会被持久化存储。当操作系统崩溃或JVM崩溃或分片故障重启时,会将Fsync前的数据恢复,会丢失Fsync之后的数据。
ES支持了配置index.translog.durability,来决定什么时候进行Fsync将Translog进行落盘:
1、request:默认,每次进行操作都会进行一次Fsync。为了数据更安全。
2、async:异步进行Fsync,默认5s进行一次,通过参数index.translog.sync_interval控制,不能低于100ms。为了性能更佳。
以上主要针对index、delete、update、bulk等写操作。
注意此配置,不影响下面的Flush,此配置的动作不会进行translog的重建以及段的提交
扩展1:为什么追加日志会比较快呢?
根据学术期刊 ACM Queue 上一张关于不同存储介质的访问性能对比图,如下所示:
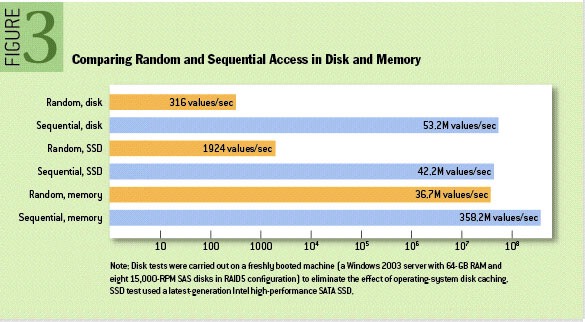
从图中可以看到磁盘/SSD顺序访问速度相当于内存随机访问速度。
文章来源传送门>
扩展2:Translog也用于搜索访问。
当使用id进行检索时,会先从段中取,段中没有,会从Translog中取。
Flush
Flush动作是指一次Lucene的commit提交和Translog重新生成过程。Flush动作会在后台自动完成,为了确保Translog不会太大,这样在数据恢复时不会花太多时间。
当Translog达到一定大小或者到默认的时间间隔,会进行一次Flush操作,比较昂贵,流程如下:
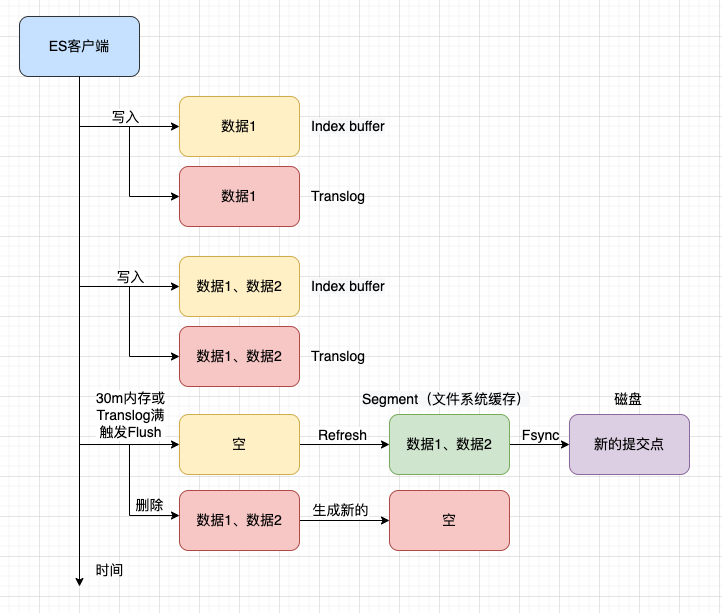
具体的执行步骤包括:
1、调用Refresh,会清空Index buffer。
2、调用文件系统缓存的Fsync操作,将Segments Fsync到磁盘,作为一个新的提交点。
3、老的Translog文件删除,因为文档都已经落盘,不需要Translog进行保障数据不丢失。
控制Flush的参数包括index.translog.flush_threshold_size和index.translog.flush_threshold_period。
index.translog.flush_threshold_size:translog达到多大时进行Flush,默认512M;
index.translog.flush_threshold_period:多久进行一次Flush,默认30分钟。
ES提供了手动Flush Api:
POST /<target>/_flush
Api传送门>
Merge
由于Refresh每秒都会创建新的段,假如每秒都有数据,那么1小时就有3600个段。
创建段会消耗文件句柄、内存和cpu运行周期,且搜索时是聚合所有的段,所以也势必会影响到搜索速度。
所以ES后台进行段的合并,小的段合并成大的段,大的段合并成更大的段。ES会使用单独的线程池自动进行合并,它会评估合并与搜索对资源的使用。
通过参数index.merge.scheduler.max_thread_count,可以控制每个分片最大可使用在合并上的线程数,默认根据节点处理器数量计算所得,计算结果最多4个,当然可以通过该参数指定。
需要知道:
1、段合并的时候会将那些旧的已删除/旧版本文档从文件系统中清除。
2、新的段会被刷(flush)到磁盘,写入一个新的提交点;段自动合并的情况下不会影响translog的变化。
3、段的合并期间不会影响索引,但它需要消耗大量I/O和CPU资源,ES默认会对合并流程进行资源限制。
ES提供了强制merge Api:
POST /<target>/_forcemerge
Api传送门>
建议操作只读索引。
整体流程
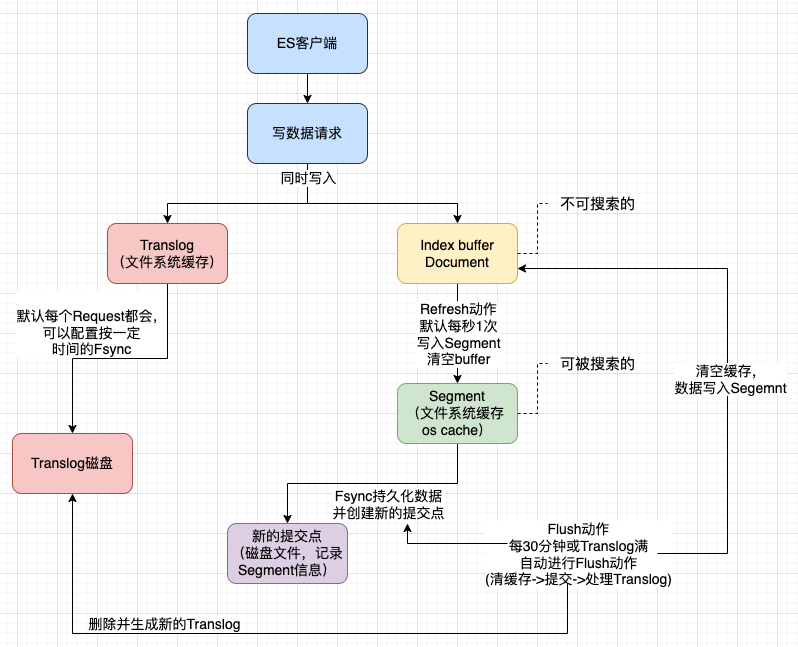
总结
ES提供了丰富的API,手动刷新、手动merge等方便我们在特殊场景下使用。
ES Translog的机制保障数据的安全性,同时文档被Refresh到Segment才能被检索到,默认是1秒,所以是近实时的搜索。
文件系统缓存,位于计算机内存和磁盘存储之间,通过它可以极大的提高了数据读写的效率。