ElasticSearch的倒排索引和列式存储
前言
在关系型数据库中,当我们有一个字段内容如 “my name is nico”,如果想要搜索字段内容含“nico”的数据。
在mysql中,需要写sql如下:select * from user where desc like ‘%nico%’,毫无疑问,它会全表扫描,也是可以查询。那如果要查询既要含”nico“又要有“luck”的情况下,同时按匹配度排序呢,优先都包含的,再包含单个的;或者查询ABCD,需要查询出A、AB、ABC等呢。
这时mysql就不适合了,ES更适合这种全文检索,它又是如何存储和检索的呢?
演示ES版本为8.6.2,系列文章同版本
倒排索引
ES的实现是基于Lucene的一个封装,Lucene是Apache一个开源的用于搜索的java包,ES封装了一套基于Json请求体的Rest api且ES具有集群的能力。
ES的一个分片就对应着Lucene的一个索引,那么文本内容在ES或者说Lucene是如何存储的呢?
一个文本类型文档字段被索引到ES,首先进行分词器分词处理成Term(词典或者Tokening),然后基于Term建立倒排索引。
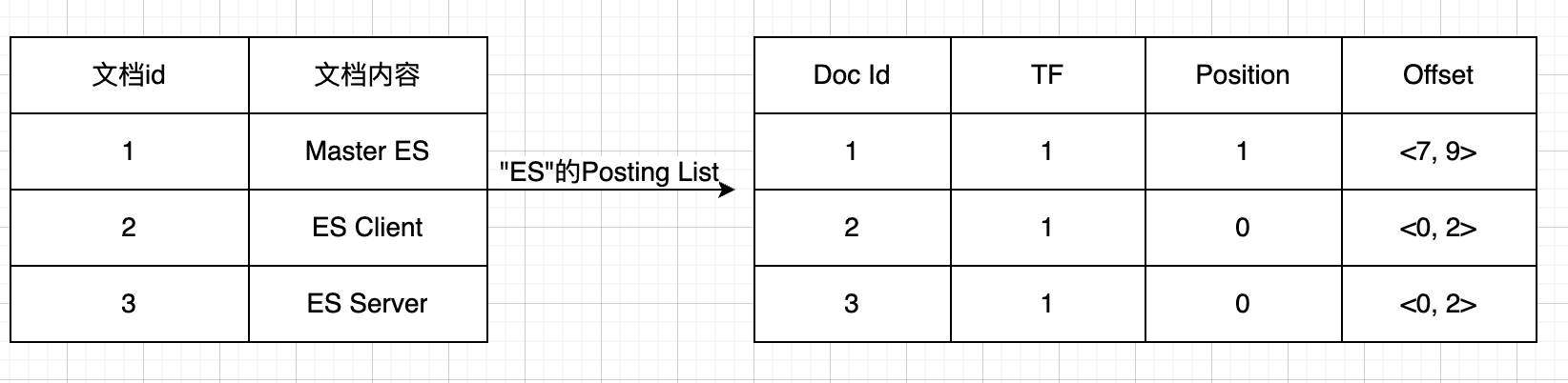
倒排索引包括了两部分,单词词典、倒排列表
单词词典 term:记录了所有文档的单词项。
倒排列表 posting list:词项对应的文档信息,包括文档Id、词频(TF)、位置(Position)、偏移(Offset)。
如下所示,“ES”这个词项与Posting list对应关系:
例如,如下两个文档,在索引后经过分词器拆分词项,然后按照字典序进行排列存储:
id=1 => “my name is nico”
id=2 => “i am nico”
倒排索引如下:
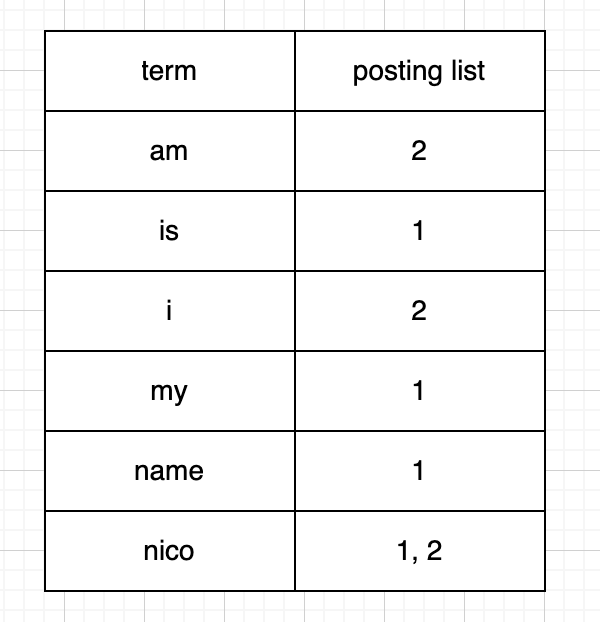
快速检索文本
ES在倒排索引的基础上加快检索效率,包括了2个方面:
1、第一个是通过空间压缩减少内存进而减少IO;
2、第二个是通过使用不同的数据结构加快检索速度。
上面提到ES倒排索引包括上面两部分 term dictionary和posting list,那么在查找一个文本时,如果term数据量太大,也会导致搜索慢,此时引入了 term index,它的数据结构可以理解为一个“Trie树”,也称为字典树,一种专门用于匹配字符串的数据结构。
字典树不会包括所有的term,它主要是通过一些公共前缀快速定位到term dictionary的某个偏移量,再继续顺序向后查询,可以缩短整个搜索的效率。
Lucene中倒排索引大概如下:
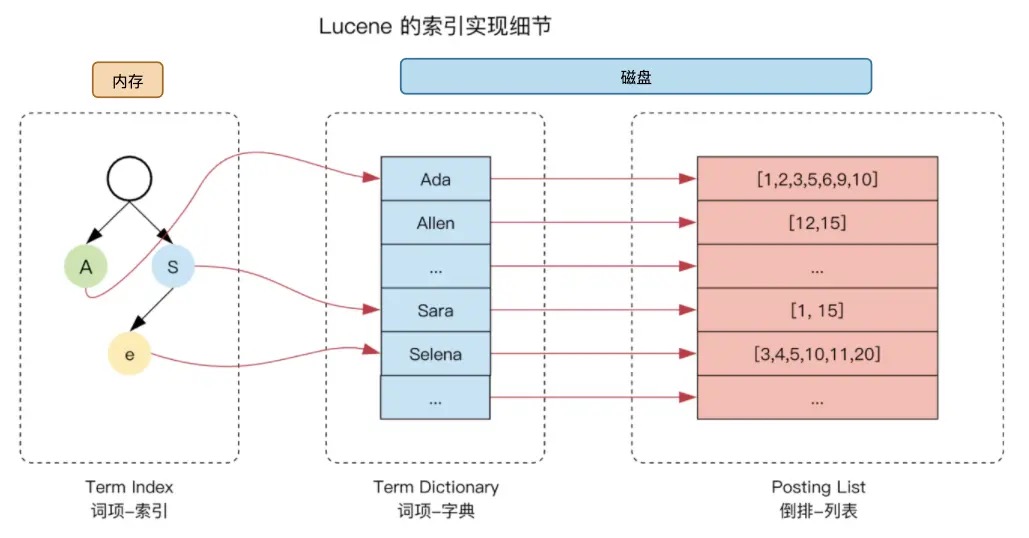
图源自网上
关于第一点压缩,在数据无规律的情况下,Lucene会将posting list的doc id进行增量编码,然后划分block进行存储。
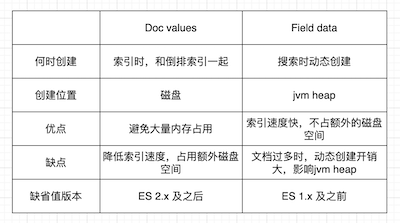
列式存储 Doc vlaues
倒排索引用于文本搜索,在查询包含某个项的文档时比较高效。但是对于确定哪些项存在某个文档中,即按字段聚合等场景,会显得比较吃力,需要遍历全部索引。
用于演示,创建一个索引 my_products :
PUT http://127.0.0.1:9200/my_products
{
"mappings":{
"properties": {
"status" :{
"type": "boolean",
"doc_values": false
}
}
}
}
本地演示,所以host使用的127.0.0.1:9200
索引一些数据:
POST http://127.0.0.1:9200/my_products/_bulk
{ "index": { "_id": 1 }}
{ "productID" : "XHDK-A-1293-#fJ3","desc":"My little iPhone", "createTime":"2023-08-16", "price": 10, "status":true}
{ "index": { "_id": 2 }}
{ "productID" : "KDKE-B-9947-#kL5","desc":"My big iPad", "createTime":"2023-08-18", "price": 20, "status":true}
{ "index": { "_id": 3 }}
{ "productID" : "JODL-X-1937-#pV7","desc":"My medium MBP", "createTime":"2023-08-20", "price": 30.5, "status":false}
对于如下搜索场景:
搜索status为true的文档,然后按价格字段进行聚合。
http://127.0.0.1:9200/my_products/_search
{
"query": {
"term": {
"status": true
}
},
"aggs": {
"agg_status": {
"terms": {
"field": "price"
}
}
}
}
结果如下:
// ... 省略部分信息
{
"hits": {
"max_score": 0.4700036,
"hits": [
{
"_index": "my_products",
"_id": "1",
"_score": 0.4700036,
"_source": {
"productID": "XHDK-A-1293-#fJ3",
"desc": "My little iPhone",
"createTime": "2023-08-16",
"price": 10,
"status": true
}
},
{
"_index": "my_products",
"_id": "2",
"_score": 0.4700036,
"_source": {
"productID": "KDKE-B-9947-#kL5",
"desc": "My big iPad",
"createTime": "2023-08-18",
"price": 20,
"status": true
}
}
]
},
"aggregations": {
"agg_status": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 10,
"doc_count": 1
},
{
"key": 20,
"doc_count": 1
}
]
}
}
}
1、搜索部分,比较简单,通过倒排索引找到status为true的文档,即找到id等于1和2的两个文档。
2、聚合部分,我们需要找到文档1和2的所有唯一的price内容,如果通过倒排索引,那么我们需要遍历所有的项才能知道,哪些属于文档1和2,这无疑是代价很高的,随着文档的增加,执行效率也会变得很低。
Doc values的出现便是为了解决这个问题,它通过倒置词项和文档这两者的关系,倒排索引是将词项映射到包含它们的文档,而Doc vlaus是将文档映射到它们包含的词项。
Doc values:docId -> terms
Doc values如何工作
Doc values和倒排索引同时生成,在索引文档的时候。也是基于Segment生成并不可变,同时序列化到磁盘中。
Doc values序列化到磁盘,不会占用jvm heap,可以充分利用操作系统的内存。当其占用内存远小于系统可用内存时,会被加载到内存中,提升访问速度,如果远大于系统内存时,会按需加载到页缓存中。
Doc values默认是开启的,除了analyzed strings(会被分词的text类型字段),其它的如数字、IP、boolean、不分词的字符都会默认开启。
analyzed strings之所以暂时还不能使用 Doc Values(当对一个text类型字段设置“doc values”为true时会报错)。文本经过分词器生成很多 Token,会导致 Doc Values 不能高效运行,而且文本类型的聚合结果一般会不符合预期。
如果某些字段不会用于聚合、排序等,可以在mapping时显示设置doc values为false,这样可以减少磁盘空间,提升索引速度。
看一个例子:
在创建索引时status被设置成doc values为false
http://127.0.0.1:9200/my_products/_search
{
"query": {
"term": {
"status": true
}
},
"aggs": {
"agg_status": {
"terms": {
"field": "status"
}
}
}
}
那么在聚合时便会报错,如下所示:
{
"type": "illegal_argument_exception",
"reason": "Can't load fielddata on [status] because fielddata is unsupported on fields of type [boolean]. Use doc values instead."
}
Doc values压缩存储
Doc values 适合聚合、排序、脚本等,属于列式存储,比较适合压缩。
特别是数字类型,可以使用以下压缩算法,ES会逐个检查:
1、如果所有的数值各不相同,设置一个标记并记录这些值;
2、如果这些值小于256,将使用一个简单编码表;
3、如果这些值大于256,检测是否存在1个最大公约数,进行除;
4、如果没有最大公约数,也可以按序,从最小的开始,统一计算偏移量进行编码(每两个值之间的差值)。
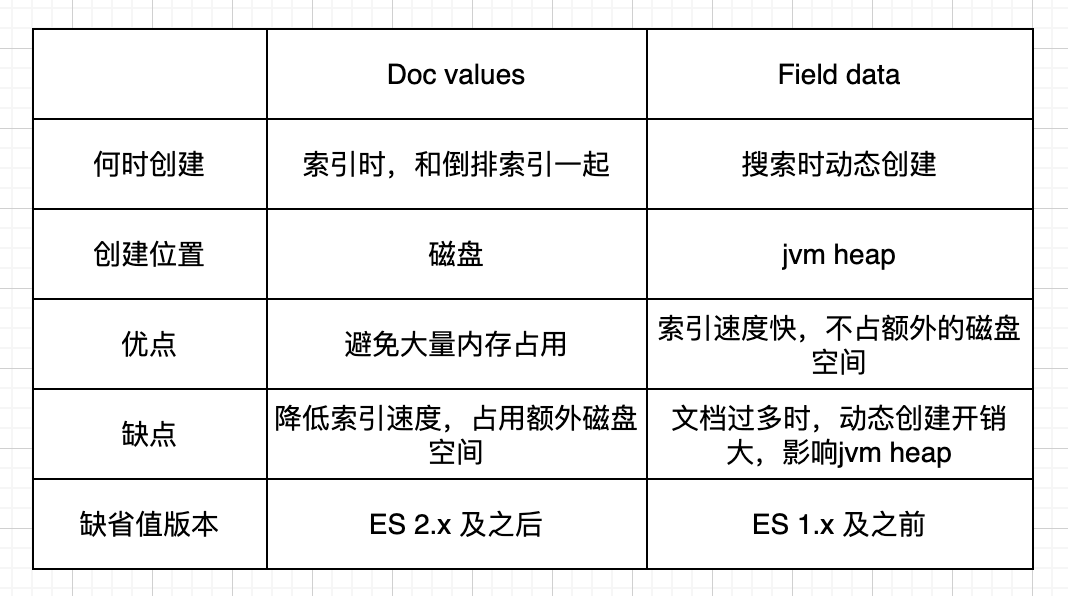
FieldData
Doc values是不支持analyzed的text字段聚合、排序等的,如果想对其进行聚合,一种方式是我们可以通过子属性keyword进行;另一种是fielddata属性。
与doc values不同,filedata这种数据结构是在查询时构建在内存中的(是一种延迟加载),是100%构建在jvm的堆内存,对内存的维护和利用是一个挑战。用的不当很容易导致OOM的发生。
如果想要在text上使用fielddata,需要在创建索引时,配置mapping属性"fielddata": true。
1、创建索引:
PUT http://127.0.0.1:9200/my_products_fielddata
{
"mappings":{
"properties": {
"desc" :{
"type": "text",
"fielddata": true
}
}
}
}
2、索引文档数据:
POST http://127.0.0.1:9200/my_products_fielddata/_bulk
{ "index": { "_id": 1 }}
{ "productID" : "XHDK-A-1293-#fJ3","desc":"My little iPhone", "createTime":"2023-08-16", "price": 10, "status":true}
{ "index": { "_id": 2 }}
{ "productID" : "KDKE-B-9947-#kL5","desc":"My big iPad", "createTime":"2023-08-18", "price": 20, "status":true}
{ "index": { "_id": 3 }}
{ "productID" : "JODL-X-1937-#pV7","desc":"My medium MBP", "createTime":"2023-08-20", "price": 30.5, "status":false}
3、按desc进行聚合
GET http://127.0.0.1:9200/my_products_fielddata/_search
{
"size" : 0,
"aggs" : {
"states" : {
"terms" : {
"field" : "desc"
}
}
}
}
结果:
// 省略部分字段
{
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"states": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "my",
"doc_count": 3
},
{
"key": "big",
"doc_count": 1
},
{
"key": "ipad",
"doc_count": 1
},
{
"key": "iphone",
"doc_count": 1
},
{
"key": "little",
"doc_count": 1
},
{
"key": "mbp",
"doc_count": 1
},
{
"key": "medium",
"doc_count": 1
}
]
}
}
}
可以看到它是经过分词的文本,然后进行的聚合,可能在某些场景不太符合预期。
如果不设置desc为fielddata为true的话,上面聚合操作会报错,如下:
{
"type": "illegal_argument_exception",
"reason": "Fielddata is disabled on [desc] in [my_products]. Text fields are not optimised for operations that require per-document field data like aggregations and sorting, so these operations are disabled by default. Please use a keyword field instead. Alternatively, set fielddata=true on [desc] in order to load field data by uninverting the inverted index. Note that this can use significant memory."
}
总结
ES相对于关系型数据库的优势,包括了全文检索和复杂检索分析,其中全文检索便是使用了ES的核心索引结构:倒排索引,它是词项映射到包含它们的文档集合的一种关系。
ES也有很多算法和数据结构来加快检索和压缩存储以降低磁盘使用。
Doc values为了优化非分词文本的其它类型数据的聚合、排序、脚本能力。它是文档到它们包含的词项的一种关系。
Fielddata是针对分词文本进行聚合检索而存在的一种数据结构,存储于jvm的内存之中。
Doc values和Fielddata的区别如下: