ElasticSearch搜索加不加keyword有什么不同呢?
前言
在项目中,通过ES检索时,对于文本字段的搜索,加.keyword和不加.keyword的表现有时并不相同,花时间做个分析和总结。
在分析前,先来看下在ES中都有哪些常见数据类型。
演示ES版本为8.6.2,后续系列文章同版本
mapping
在我们索引一个文档后,可以通过API:{index}/_mapping 查看文档的数据类型。
创建一个关于商品的索引用于演示,定义索引名称为 products
POST http://127.0.0.1:9200/products/_bulk
{ "index": { "_id": 1 }}
{ "productID" : "XHDK-A-1293-#fJ3","desc":"iPhone" }
{ "index": { "_id": 2 }}
{ "productID" : "KDKE-B-9947-#kL5","desc":"iPad" }
{ "index": { "_id": 3 }}
{ "productID" : "JODL-X-1937-#pV7","desc":"MBP" }
特别注意,该Api需要在body最后做个换行,不然会报错:The bulk request must be terminated by a newline
索引及文档已经创建成功,通过 products/_search 可查看索引数据。
通过 products/_mapping 查看字段类型映射:
// GET http://127.0.0.1:9200/products/_mapping
// 结果:
{
"products":{
"mappings":{
"properties":{
"desc":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":256
}
}
},
"productID":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":256
}
}
}
}
}
}
}
可以看到默认将字符串类型数据,映射成ES text类型,同时在这个字段下,定义了一个keyword(第2个)类型的子字段叫”keyword”(第1个)
这便利用到了ES最重要的特性之一:Dynamic mapping。
只需要你索引一个文档,默认会自动创建索引及根据文档中字段的类型映射到ES中的数据类型。
具体的行为由dynamic参数控制,默认为true,表示自动映射。
ES中自动映射的数据类型,如下图所示:

图来自ES官方,地址传送门>
第一列是文档的原始据类型;第二列是dynmic配置为true时对应ES的类型;第三列是配置runtime时的ES类型。
图中仅表示自动映射的字段,ES还有很多其它类型,如Integer、Boolean等,需要创建索引时显示的配置mapping来完成。
可以看到最后一行,关于字符串类型:
String如果不是时间或数字内容,便会映射成 text 类型同时有一个子属性 keyword 类型。
那 text类型和keyword类型,有会有什么不同呢?
text类型
你也可以理解它是一个full-text字段类型,意思是一个文本串在索引和检索时,会被ES通过分词器进行拆分成一组词项。
分词器后面通过单独一篇进行介绍。暂时可以理解会将一个字符串拆分成多个词。
例如字符串:“good luck”,经过分词器后,会被拆分成:“good”和“luck” 两个词项,通过倒排索引可进行全文搜索。
特点:
1、内容会被分词器解析成多个词
2、支持全文检索,通常使用match查询,进行算分
3、不用于排序、也基本不用于聚合操作(不准确)
keyword类型
keyword关键字类型适合于结构化的数据,如id、邮件、电话等。
它默认会以doc_value的方式存储到磁盘,一种正向的列式存储方式,用于排序、聚合和精确查询。
例如下面显示定义phone字段为keyword类型:
{
"mappings": {
"properties": {
"phone": {
"type": "keyword"
}
}
}
}
特点:
1、内容不会被分词器进行分词
2、用于精确查询,通常使用term查询(term也不会分词)
3、用于排序和聚合
加不加keyword的区别
通过上面索引的文档,进行如下演示:
说明一点:大写字符经过默认分词器后会变小写。
所以,如上面文档
{ \"productID\" : \"XHDK-A-1293-#fJ3\", \"desc\": \"iPhone\" }
索引后,原始数据搜索,如下所示:
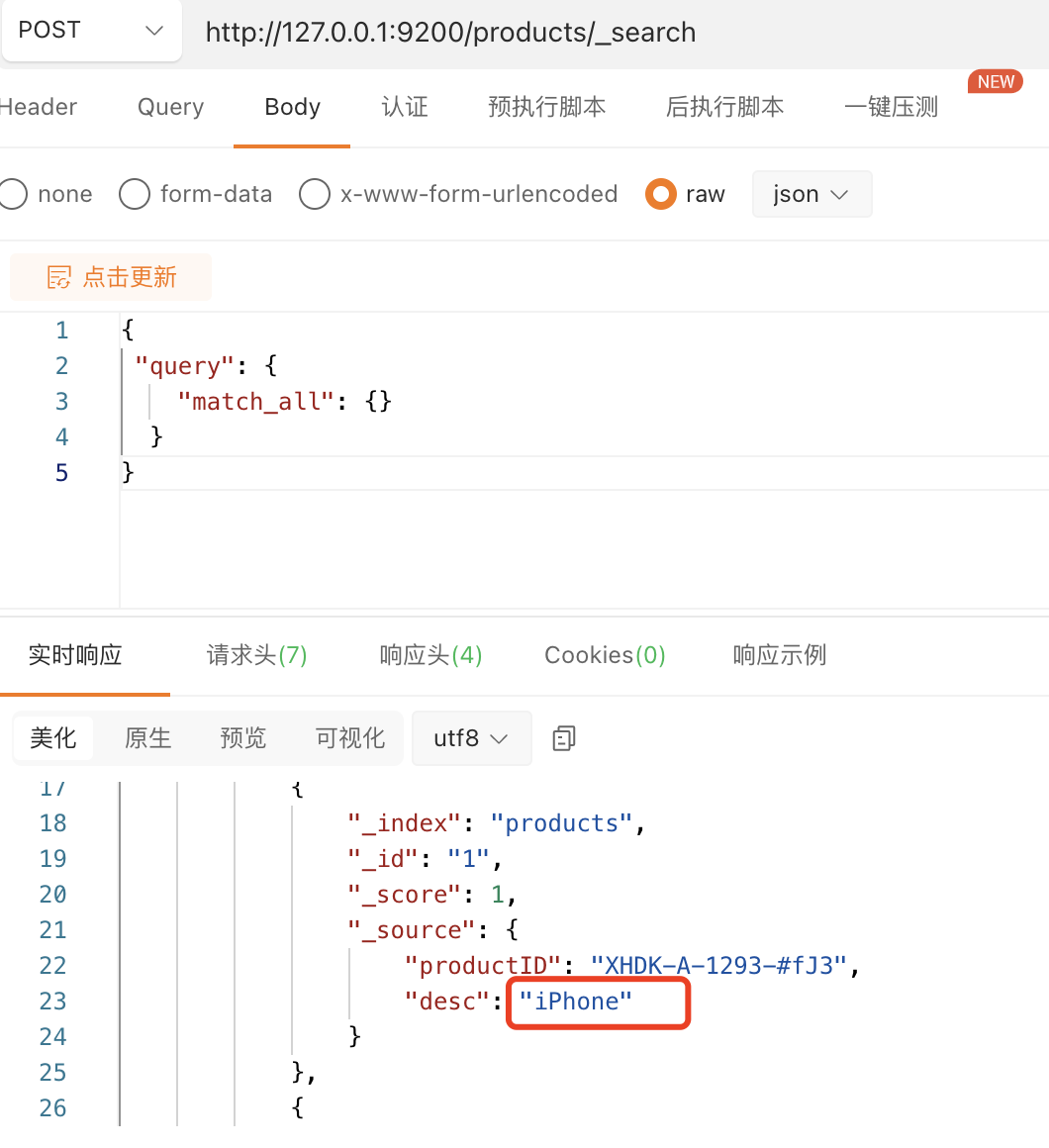
分析下desc字段值会被存储成小写在倒排索引中:iphone,如下所示:
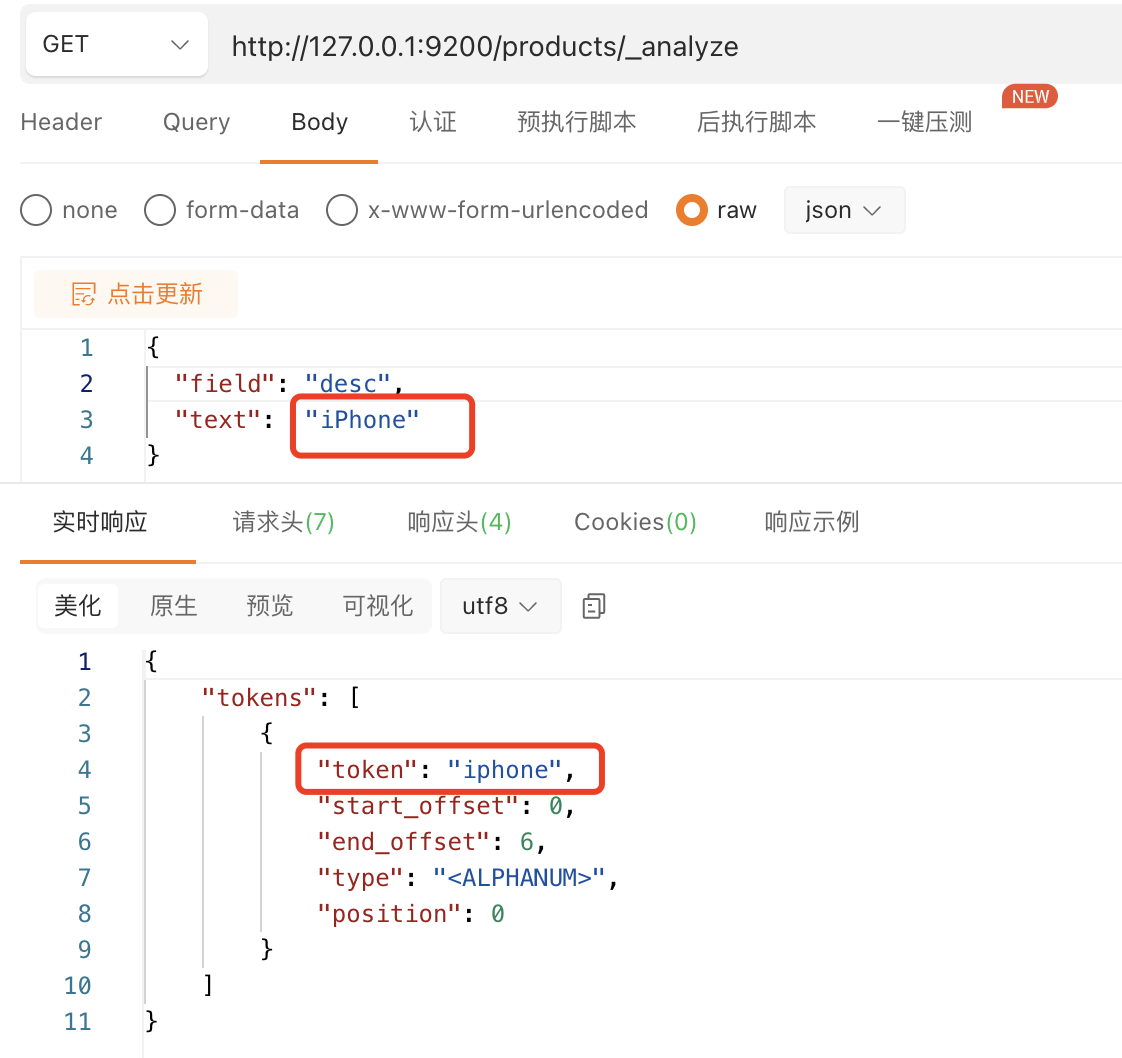
请求body中 可以增加 “explain”: true,查看更详细信息。
下面提到的大写值是iPhone,小写值是iphone。
1、term查询,不带关键词keyword,大写值
{
"query": {
"term": {
"desc": {
"value": "iPhone"
}
}
}
}
结果:搜索不到,term使其没有经过分词器,iPhone 匹配不到 倒排索引词iphone。
2、term查询,不带关键词keyword,小写值
{
"query": {
"term": {
"desc": {
"value": "iphone"
}
}
}
}
结果:搜索到,得分 “_score”: 0.9808291,term使其没有经过分词器,iphone 匹配到 倒排索引词iphone。
3、term查询,带关键词keyword,大写值
{
"query": {
"term": {
"desc.keyword": {
"value": "iPhone"
}
}
}
}
结果:搜索到,得分"_score": 0.9808291,term和keyword使其没有经过分词器,keyword属性在索引(创建)文档时也没有进行分词,存于doc_value,所以匹配到,精确匹配。
4、term查询,带关键词keyword,小写值
{
"query": {
"term": {
"desc.keyword": {
"value": "iphone"
}
}
}
}
结果:搜索不到,term和keyword使其没有经过分词器,iphone 匹配不到 索引中的 desc子属性keyword关键词 iPhone。
5、match查询,带关键词keyword,小写值
{
"query": {
"match": {
"desc.keyword": "iphone"
}
}
}
结果:搜索不到,keyword使其没有经过分词器,iphone 匹配不到 索引中的 desc子属性keyword关键词 iPhone。
大写iPhone可以,结果同3。
所以,搜索时使用term或属性.keyword后,搜索不会进行分词,会进行精确匹配原始的文档数据字符串。
总结
默认索引一个文档,会根据Dynamic mapping 映射文档类型,对于字符串(非时间和数字串)会映射成ES的 text类型,同时生成一个 keyword子类型的属性。
在搜索时,一般有keyword时用与精确查询、排序、聚合;精确查询通常结合term进行搜索。
keyword关键词搜索不会进行分词,匹配原始文档数据。