ElasticSearch的_reindex操作
前言
在使用ES的时候,有些配置一旦确定是不支持修改的,例如以下场景:
1、修改mappings配置,如某个字段的类型或属性:默认情况下,动态mapping支持新增字段,不允许修改。
2、创建索引时主分片数一旦确定也是不能修改的。
3、索引的分词规则:使用了新的分词器或修改了后,之前索引的数据是使用老的分词器索引的,此时也需要索引重建。
以上场景,都需要重建索引,ES也提供了_reindex的api,应对以上场景。
概念
_reindex api 官方地址传送门>
功能就是将一个索引的文档copy到另一个索引上,它是以一种快照的方式进行的。
底层使用了两个api:先通过scroll api将文档从源索引中查询出来,再通过bulk api将文档写入新的索引中。
所以,对于源索引的mappings的配置以及主副分片的数量等是不会被reindex到新的索引上的,需要提前按需创建新的索引,如果不创建目标索引,那么会按集群或模板自动完成索引的创建。
最基础的示例:
1、先创建源索引 my_products
PUT http://127.0.0.1:9200/my_products
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
}
}
2、索引部分文档
POST http://127.0.0.1:9200/my_products/_bulk
{ "index": { "_id": 1 }}
{ "productID" : "XHDK-A-1293-#fJ3","desc":"My little iPhone", "createTime":"2023-08-16", "price": 10, "status":true}
{ "index": { "_id": 2 }}
{ "productID" : "KDKE-B-9947-#kL5","desc":"My big iPad", "createTime":"2023-08-18", "price": 20, "status":true}
{ "index": { "_id": 3 }}
{ "productID" : "JODL-X-1937-#pV7","desc":"My medium MBP", "createTime":"2023-08-20", "price": 30.5, "status":false}
3、创建目标索引 products_new
PUT http://127.0.0.1:9200/products_new
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
}
}
4、使用 _reindex api
POST http://127.0.0.1:9200/_reindex
{
"source": {
"index": "my_products",
},
"dest": {
"index": "products_new"
}
}
source:指定源索引信息;dest指定目标索引信息。
5、查看索引 products_new 数量:
GET http://127.0.0.1:9200/products_new/_count
下面演示示例,没有特别说明,均在1、2、3的基础上进行。
第3步也可以省略,可以配置个index template,在reindex自动创建目标索引。
常见场景
文档处理相关
1、reindex特定文档
通过query查询源索引特定的文档进行reindex。
POST http://127.0.0.1:9200/_reindex
{
"source": {
"index": "my_products",
"query":{
"term":{
"status": true
}
}
},
"dest": {
"index": "products_new"
}
}
只reindex源索引中文档的status为true的文档。
2、reindex部分字段
可以通过 _source 过滤源索引的部分字段。
记得先删除原来的目标索引并重新创建。
POST http://127.0.0.1:9200/_reindex
{
"source": {
"index": "my_products",
"_source": ["status", "productID"]
},
"dest": {
"index": "products_new"
}
}
通过 _search api查看全部文档:
GET http://127.0.0.1:9200/products_new/_search
{
"query": {
"match_all":{}
}
}
搜索显示只索引了status和productID两个字段;另外_id也同步了。
3、修改字段名或新增字段
可以使用 script 进行字段和逻辑处理。
例如:需要将status 修改名称为 state,可以按如下处理:
POST http://127.0.0.1:9200/_reindex
{
"source": {
"index": "my_products"
},
"dest": {
"index": "products_new"
},
"script": {
"source": "ctx._source.state = ctx._source.remove(\"status\")"
}
}
通过 _search api查看,部分文档如下:
{
"_index": "products_new",
"_id": "1",
"_score": 1,
"_source": {
"productID": "XHDK-A-1293-#fJ3",
"createTime": "2023-08-16",
"price": 10,
"state": true,
"desc": "My little iPhone"
}
}
status 变成了 state字段
如果要新增字段,script可以定义如下source:
"source": "ctx._source.newField = ctx._source.desc + '_' + ctx._source.status"
多个字段写法:
"source":
"""
ctx._source.newField = ctx._source.desc + '_' + ctx._source.status;
ctx._source.newField2 = ctx._source.price + '_' + ctx._source.status;
"""
4、版本冲突
如果dest索引已经有了部分数据,可以指定不同的策略应对version上的冲突,通过指定dest索引的version_type,如下:
- version_type省略或者设置internal ,可以直接覆盖具有相同id的文档,同时目标索引文档的版本号加1。
- version_type设置external,目标索引文档会使用源索引的文档版本,id对应文档不存在时,进行创建;id对应文档存在时,如果目标索引文档版本更低,则更新,否则会提示冲突(默认当前批次处理完,中断后续批次处理)。
1)、演示 version_type = internal
先进行一次reindex:
POST http://127.0.0.1:9200/_reindex
{
"source": {
"index": "my_products"
},
"dest": {
"index": "products_new"
}
}
查看目标索引 products_new 文档版本:
增加参数 ?version=true
GET http://127.0.0.1:9200/products_new/_search?version=true
{
"query": {
"match_all": {}
}
}
部分结果如下:
{
"_index": "products_new",
"_id": "1",
"_version": 1,
"_score": 1,
"_source": {
"productID": "XHDK-A-1293-#fJ3",
"desc": "My little iPhone",
"createTime": "2023-08-16",
"price": 10,
"status": true
}
}
版本号为1
再指定 version_type = internal,进行一次reindex:
可以看到 _reindex 返回显示是更新了文档,没有创建文档。
再次 _search?version=true 搜索,部分结果如下,文档version变成2,在原来基础上增加了1,因为文档执行了更新。
{
"_index": "products_new",
"_id": "1",
"_version": 2,
"_score": 1,
"_source": {
"productID": "XHDK-A-1293-#fJ3",
"desc": "My little iPhone",
"createTime": "2023-08-16",
"price": 10,
"status": true
}
},
2)、演示 version_type = external
先删除演示1中的目标索引
执行如下reindex,指定version_type:
POST http://127.0.0.1:9200/_reindex
{
"source": {
"index": "my_products"
},
"dest": {
"index": "products_new",
"version_type": "external"
}
}
查询目标索引及数据,成功,文档version均为1
此时目标索引已存在,相同的body,再次reindex,所有文档报错如下,版本冲突,因为verison相等了:
{
"index": "products_new",
"id": "1",
"cause": {
"type": "version_conflict_engine_exception",
"reason": "[1]: version conflict, current version [1] is higher or equal to the one provided [1]",
"index_uuid": "zG2deNneRwWVpvnl4bMUSw",
"shard": "0",
"index": "products_new"
},
"status": 409
}
更新源索引 my_products 文档id=1的文档,其版本更新为2。
相同的body(version_type = external),再次执行reindex,此时id=1的文档reindex成功,另外2个仍然冲突(源索引共3个文档)。
默认情况下,某批次的文档出现版本冲突会中断reindex后续批次处理,可以通过配置 conflicts 来忽略冲突,继续执行,如下所示:
POST http://127.0.0.1:9200/_reindex
{
"conflicts": "proceed",
"source": {
"index": "my_products"
},
"dest": {
"index": "products_new",
"version_type": "external"
}
}
conflicts默认是“abort”配置
性能相关
1、指定每批次查询的数据量
默认size大小为1000,可以通过指定size来提高reindex的速度。
POST http://127.0.0.1:9200/_reindex
{
"source": {
"index": "my_products",
"size": 1
},
"dest": {
"index": "products_new",
}
}
返回结果如下:
{
"took": 1407,
"timed_out": false,
"total": 3,
"updated": 0,
"created": 3,
"deleted": 0,
"batches": 3,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1,
"throttled_until_millis": 0,
"failures": []
}
可以看到 batches 的值为3(源索引共3个文档,每批次1个,共3/1批次)
2、异步reindex
reindex默认超时时间1m(分钟),如果数据量比较大,可能会导致超时中断,可以通过指定 rul参数 wait_for_completion = false 进行异步处理,如下:
POST http://127.0.0.1:9200/_reindex?wait_for_completion=false
{
"source": {
"index": "my_products",
"size": 1
},
"dest": {
"index": "products_new"
}
}
返回任务id:
{
"task": "Y7r8Iz33QHCi3oDq3HCwEg:1475243"
}
通过 _task/<taskId> 查看任务进度:
GET http://127.0.0.1:9200/_tasks/Y7r8Iz33QHCi3oDq3HCwEg:1475243
返回如下:
{
"completed": true,
"task": {
"node": "Y7r8Iz33QHCi3oDq3HCwEg",
"id": 1475243,
"type": "transport",
"action": "indices:data/write/reindex",
"status": {
"total": 3,
"updated": 0,
"created": 3,
"deleted": 0,
"batches": 3,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1,
"throttled_until_millis": 0
},
"description": "reindex from [my_products] to [products_new]",
"start_time_in_millis": 1694449113170,
"running_time_in_nanos": 1679822000,
"cancellable": true,
"cancelled": false,
"headers": {}
},
"response": {
"took": 1408,
"timed_out": false,
"total": 3,
"updated": 0,
"created": 3,
"deleted": 0,
"batches": 3,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled": "0s",
"throttled_millis": 0,
"requests_per_second": -1,
"throttled_until": "0s",
"throttled_until_millis": 0,
"failures": []
}
}
可以看到,任务成功,创建了3条文档,分了3个批次等信息。
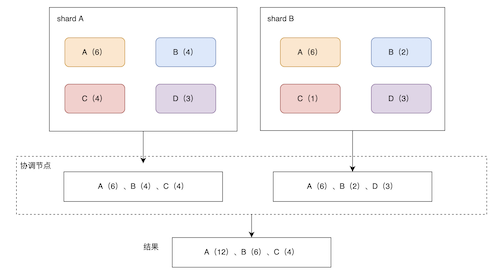
3、Slicing 切片查询
reindex支持分片滚动来并行化处理过程,这种并行可以提高效率,为将请求分解为更小的部分提供了一种方便的方法。
它分为手动和自动两种:手动和自动
1)、手动切片 Manual slicing
在source索引中增加配置如下:
// 第一个
{
"source": {
"index": "my_products",
"slice": {
"id": 0,
"max": 2
}
},
"dest": {
"index": "products_new"
}
}
// 第二个
{
"source": {
"index": "my_products",
"slice": {
"id": 1,
"max": 2
}
},
"dest": {
"index": "products_new"
}
}
slice.id 指定分片id;slice.max 指定分片数量。
注意:slice.id 需要 小于slice.max字段,slice.max 必须大于1。
如果将slice.max设置成2,那么会分成两个切片进行获取目标索引文档,两个切片的数据并集等价于不分片的数据。
1)、自动切片 Automatic slicing
通过指定 url参数 ?slices={num} 指定切片数,进行自动完成切片处理,一次请求即可,如下所示:
POST http://127.0.0.1:9200/_reindex?slices=3
{
"source": {
"index": "my_products"
},
"dest": {
"index": "products_new"
}
}
结果如下:
{
"took": 1637,
"timed_out": false,
"total": 3,
"updated": 0,
"created": 3,
"deleted": 0,
"batches": 2,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1,
"throttled_until_millis": 0,
"slices": [
{
"slice_id": 0,
"total": 2,
"updated": 0,
"created": 2,
"deleted": 0,
"batches": 1,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1,
"throttled_until_millis": 0
},
{
"slice_id": 1,
"total": 1,
"updated": 0,
"created": 1,
"deleted": 0,
"batches": 1,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1,
"throttled_until_millis": 0
},
{
"slice_id": 2,
"total": 0,
"updated": 0,
"created": 0,
"deleted": 0,
"batches": 0,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1,
"throttled_until_millis": 0
}
],
"failures": []
}
可以看到,分了3个切片进行reindex,因为数据量太少,有个slice没有分配到文档,理论上是平分。
在使用slice时注意点:
1、当slice切片数等于索引的分片数时,处理效率最高。
2、如果切片数很大(如500),远大于索引分片数时,反而会影响效率。
总结
ES提供了reindex的api在一些场景还是比较有用的,能够可配置且高效的完成数据的重新索引,对于只有一个1主分片,文档大概6w+的源索引, reindex时size改成5千,其它默认,基本上秒级别可以完成处理。
reindex支持做字段的特殊处理,支持只reindex特定文档,支持目标索引 ingest_pipeline处理等等多个功能。
但reindex是一个一次性的动作,其基于源索引文档快照完成。