Ollama+Higress+LobeChat部署高可用大模型集群
前言
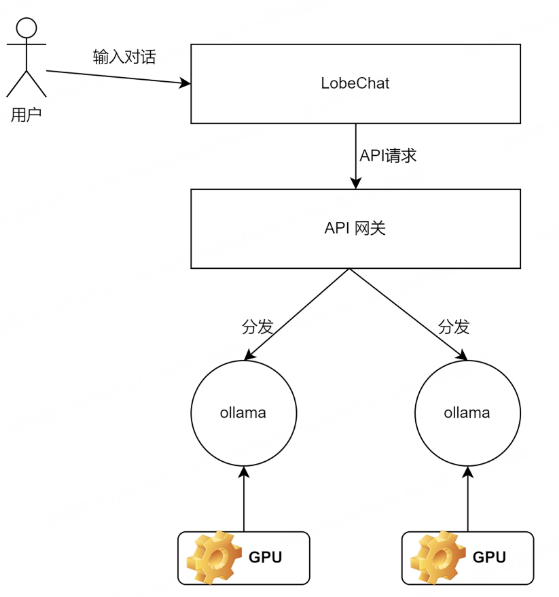
本地模型部署,比较常见的方式有Ollama和vLLM,之前使用vLLM + Open WebUI完成了DeepSeek-r1-Distill-Qwen-1.5B模型,vLLM比较适合生产环境使用,其通过内存优化和连续批处理技术,使得模型具有高效的推理能力,一些云厂商通过vLLM私有化部署模型。本篇会继续使用Ollama + Higress + LobeChat,完成模型部署及使用阿里云AI Ingress负载均衡,最后通过LobeChat实现问答。
Ollama
Ollama是一个专门在本地机器上便捷部署和运行大模型(LLM)的开源框架,仅需要简单的命令就能下载并运行多种大模型,如DS、Qwen、Llama3等。
Ollama专注于简易及轻量化部署,同时针对所有模型封装了统一的API,并且兼容OpenAI。
Higress
Higress转为AI问答场景设计的网关服务,阿里开源项目。内核基于Istio和Envoy,实现了负载均衡、流式响应、监控等,支撑阿里百炼API、千问APP、机器学习PAI平台等AI服务。同时解决了阿里内部Tengine reload对长连接有损问题。
LobeChat
LobeChat类似OPen WebUI,属于一个开源ChatGPT/LLMs聊天应用与开发框架。
环境准备
仍然使用阿里云的GPU云服务器,选购如下:
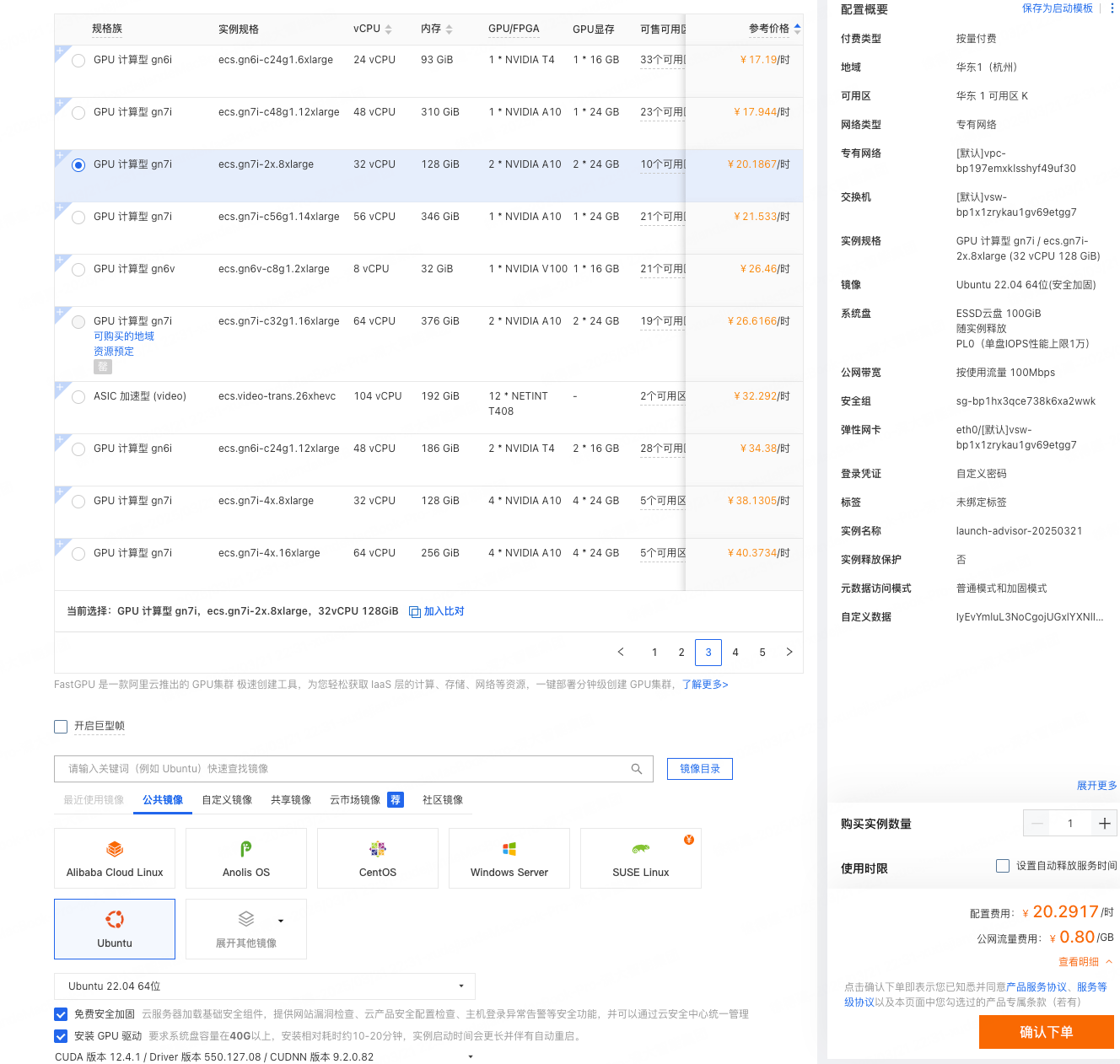
- 显存:2个NVIDIA A10,2 * 24G
- CPU:32C
- 内存:128G
- SSD云盘:100G
- 带宽:100M
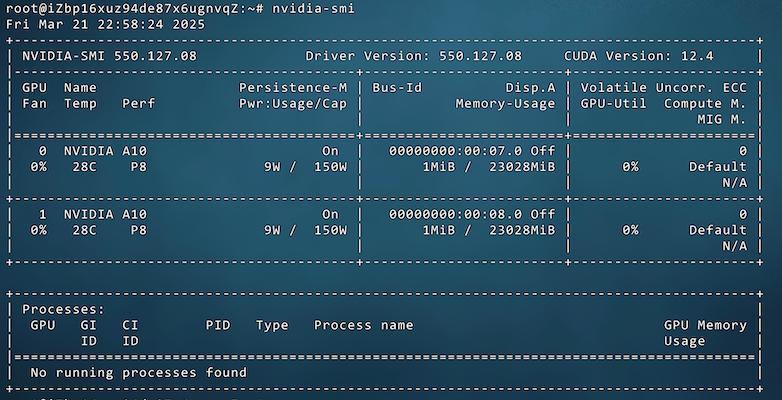
使用ssh登录成功后,确认GPU已安装完成,输入:nvidia-smi
紧接着安装Docker,参考文档>。
并配置阿里云镜像加速器,在/etc/docker/daemon.json增加:
{
"registry-mirrors": [
"https://kkk3bt3i.mirror.aliyuncs.com"
]
}
部署
架构
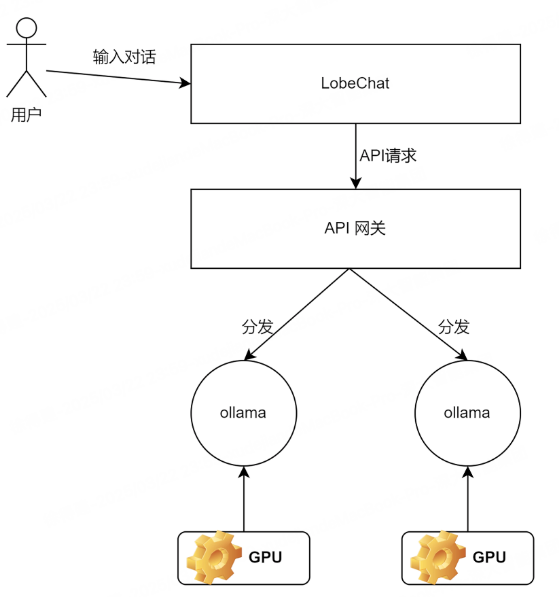
拉取并启动Ollama镜像
1、拉取镜像,指定了docker.1ms.run代理地址:
docker pull docker.1ms.run/ollama/ollama:0.5.11
2、启动镜像,启动两个,用来进行负载均衡调用:
2.1、docker run -dp 8880:11434 --gpus device=0 --name DeepSeek-R1-1 docker.1ms.run/ollama/ollama:0.5.11
说明:
- -dp 8880:11434,将容器的11434端口映射到宿主机8880端口
- –gpus device=0,容器使用GPU 0号卡,使用nvidia-smi 命令得到的两个GPU卡号0和1
- –name DeepSeek-R1-1,指定容器名称
- docker.1ms.run/ollama/ollama:0.5.11,刚才拉取的镜像名
2.2、docker run -dp 8881:11434 --gpus device=1 --name DeepSeek-R1-2 docker.1ms.run/ollama/ollama:0.5.11
使用不同的宿主机端口、GPU卡号和容器名称
问题记录
docker run运行容器报错如下:
docker: Error response from daemon: could not select device driver “” with capabilities: [[gpu]]
原因:没有安装NVIDIA Container Toolkit
NVIDIA Container Toolkit 是 NVIDIA 官方推出的一套工具链,旨在解决容器化环境中 GPU 资源访问的复杂性问题。它允许用户在 Docker 等容器平台中直接使用 NVIDIA GPU,从而在容器中运行需要 GPU 支持的应用程序,如深度学习训练、推理、科学计算等
依次执行如下命令完成安装:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
apt-get update
apt-get install -y nvidia-docker2
systemctl restart docker
后执行docker run,容器启动Ollama容器。
Ollama常见命令
- ollama run <model_name>:运行指定模型并进入交互模式。
- ollama pull <model_name>:从远程仓库拉取指定模型到本地。
- ollama list:列出本地已下载的所有模型。
- ollama rm <model_name>:删除本地指定的模型。
- ollama show <model_name>:显示指定模型的详细信息。
- ollama create <model_name> -f **:根据Modelfile创建自定义模型。
- ollama cp <source_model> <destination_model>**:复制一个模型并创建新副本。
- ollama serve:启动Ollama服务,允许通过HTTP请求与模型交互。
- ollama stop:停止正在运行的Ollama服务。
- ollama ps:列出当前正在运行的模型实例
部署DeepSeek-R1
通过Ollama官方地址搜索DeepSeek,包括了从蒸馏1.5b到官方版671b
这里以deekseek-r1:1.5b为例运行。有两种方式启动Ollama,一种是本地下载后挂载到容器内使用,一种是容器内容下载模型。因为第一种方式过慢,使用容器内启动容器的方式,但更推荐挂载的方式。
第一种方式,使用本地下载并挂载到容器:
# 服务器上下载并运行ollama工具(工具下载太慢)
curl -fsSL https://ollama.com/install.sh | sh
# 模型拉取
ollama pull deepseek-r1:1.5b
# 启动Ollama,使用模型挂载
docker run -dp 8880:11434 --runtime=nvidia --gpus device=0 --name DeepSeek-R1-1 -v /usr/share/ollama/.ollama/models:/root/.ollama/models docker.1ms.run/ollama/ollama:0.5.11
# 查看现有的模型
docker exec -it <容器ID> ollama list
其中:/usr/share/ollama/.ollama/models:/root/.ollama/models 是启动Ollama容器时配置,宿主机的目录 usr/share/ollama/.ollama/models 被映射到容器的目录 /root/.ollama/models。
第二种方式,进入容器后进行拉取启动:
# 进入容器
docker exec -it <容器名称或 ID> /bin/bash
# 运行模型,如果本地没有模型,会进行下载,下载完成后完成容器的加载
ollama run deepseek-r1:1.5b
测试模型效果:
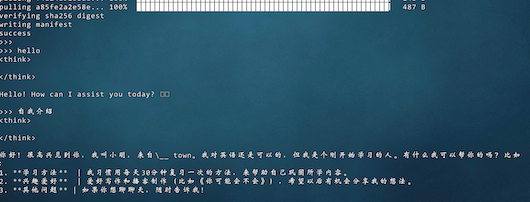
也可以在机器节点上运行命令,基于OpenAI规范进行api调用:
curl http://localhost:8880/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-r1-think:1.5b",
"messages": [
{"role": "user", "content": "hello"}
]
}'
问题记录
模型输出并没有think
原因:查看模型的聊天模版
执行 ollama show --modelfile deepseek-r1:1.5b,可以看到在 <| Assistant| > 后面直接就是跟的 Content,没有可以强调 的事情,因此就相当于把是否 think 的主动权交给大模型了。
解决:如果想要强制,需要在 <| Assistant| > 后面加一个 <think>\\n 标签,操作步骤如下:
# 先将聊天模版保存下来
ollama show --modelfile deepseek-r1:1.5b > Modelfile
# 再修改模版
<| Assistant| > 后面加一个 `<think>\\n` 标签
# 基于Modelfile创建新的模型
ollama create deepseek-r1-think:1.5b -f ./Modelfile
测试后发现具有think的输出。
Higress AI网关部署
使用 docker 进行部署
# 下载安装脚本
curl -sS https://higress.cn/ai-gateway/install.sh
# 修改脚本,支持公网访问
去掉脚本中如下内容:`127.0.0.1:`
# 执行脚本,如果没有权限,可以使用 chmod +x install.sh 授权
sudo ./install.sh
出现 Happy Higressing!,则表示启动成功了。从输出内容也可以看出,Higress共暴露了三个端口:
- HTTP 访问端口8080
- HTTPS 访问端口8443
- 控制台访问端口8001
配置路由
使用 公网:8001 访问控制台,注意端口增加安全组。
首先配置AI服务提供者,包括两个模型:

然后配置AI路由,按比例各50%进行访问,注意地址使用的是公网地址,因为Higress运行在Docker容器中,访问不到服务器内网:
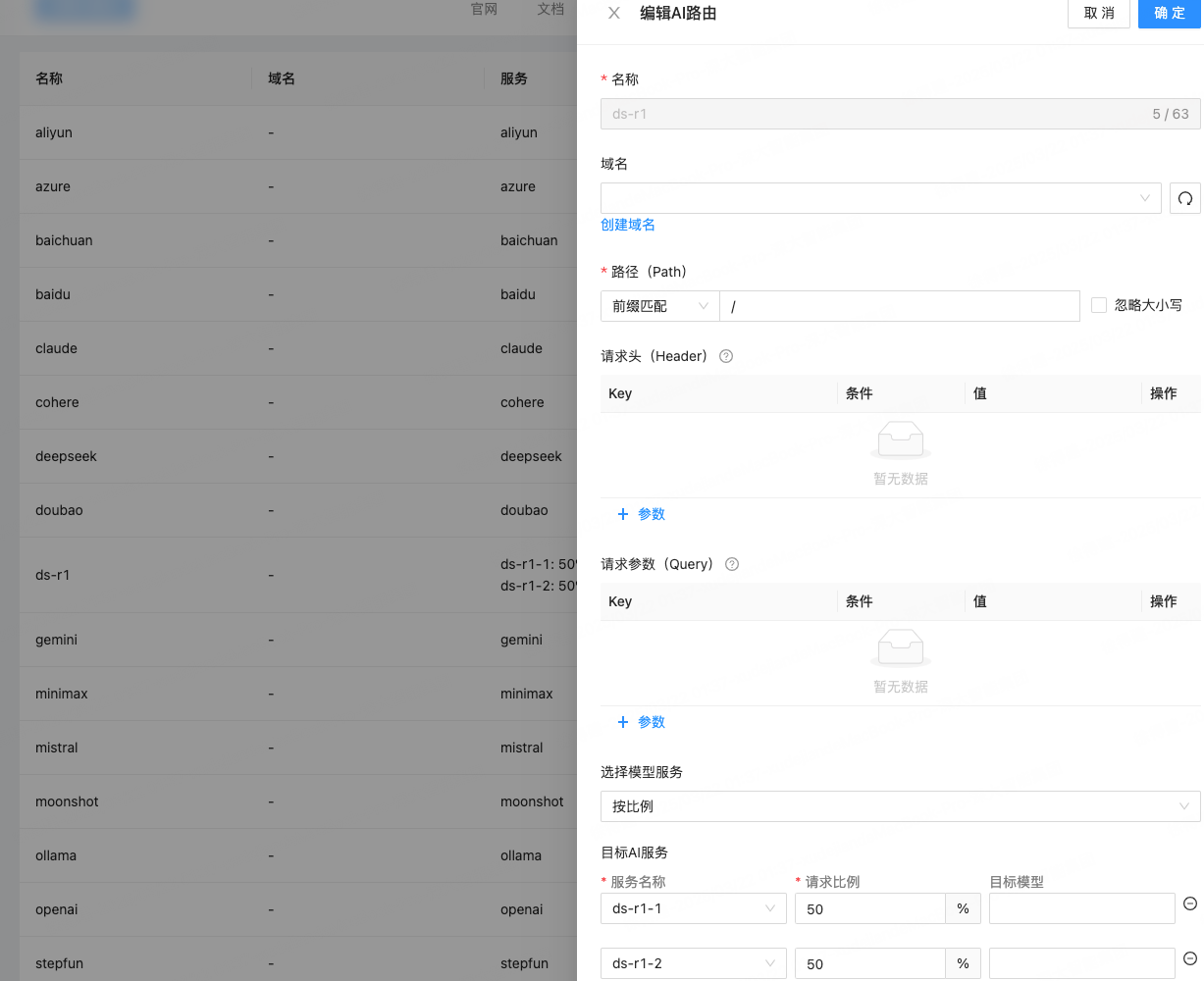
在服务器节点上访问网关,接口符合OpenAI规范:
curl -sv http://127.0.0.1:8080/v1/chat/completions -X POST -H 'Content-Type: application/json' -d '{
"model": "deepseek-r1:1.5b",
"messages": [
{
"role": "user",
"content": "自我介绍,中文回答问题"
}
]
}'
问题记录
通过上面的curl访问一直报错:
{“error”:{“message”:“Authentication Fails (no such user)”,“type”:“authentication_error”,“param”:null,“code”:“invalid_request_error”}}r
原因:Higress默认有一个deepseek的路由,基于模型名称前缀匹配deepseek,因为上面测试使用的模型名称是deepseek-r1:1.5b,所以导致路由到deepseek路由,故而报错。
解决:将自带的deepseek路由修改路由规则,避免冲突。
部署LobeChat
LobeChat的部署包括了两种类型,一种是新手体验版,历史数据及配置信息都在LobeChat的云端;第二种是完全私有化部署。本篇以新手版为例进行演示。
使用Docker进行启动:
docker run -d -p 3210:3210 \
-e OPENAI_API_KEY=unused \
-e OPENAI_PROXY_URL=http://公网地址:8080/v1 \
-e ACCESS_CODE=lobe66 \
--name lobe-chat \
lobehub/lobe-chat
公网地址:8080是Higress网关的访问地址,记得增加端口安全组。
在浏览器输入 公网:3210,即打开LobeChat对话客户端,完成流式会话。
总结
Ollama + Higress + LobeChat实现本地化部署高可用可控的大模型集群。通过此方式部署1.5b等低参数模型,因为单个节点的GPU是有上限的,如果是7610B大规模的参数量,就需要使用多个节点完成一个模型的启动,需要考虑使用分布式计算框架,多节点分片存储,如Ray框架。