Linux网路包收发流程
前言
文章会先简单介绍网络模型,主要是更为实用的TCP/IP模型;再介绍关于Linux内核网络栈;最后重点分析关于底层的网络包收发流程,熟悉底层收发流程对于我们掌握IO模型或者日常开发中涉及网络接口的底层传输会更加清晰和易懂。
TCP/IP网络模型
经常被提起的七层模型和四层模型,前者指的是OSI模型,包括应用层、表示层、会话层、传输层、网络层、数据链路层、物理层;而后者指的是TCP/IP模型,包括应用层、传输层、网络层、网络接口层。在Linux操作系统中,使用的是更为实用的TCP/IP模型。
在TCP/IP模型中,不同层的职责如下:
- 应用层(对应OSI的前三层):负责向用户提供应用程序,如HTTP、FTP、DNS等。
- 传输层(对应OSI的传输层):负责端到端的通讯,比如TCP、UDP等。
- 网络层(对应OSI的网络层):负责网络包封装、寻址和路由,比如IP、ICMP等。
- 网络接口层(对应OSI数据链路和物理层):负责网络包在物理网络中的传输,比如MAC寻址、错误侦测及网络中传输网络帧等。
Linux内核网络栈
有了TCP/IP模型后,在进行网络数据发送的时候,每层会对上一层发来的数据进行处理,加上自己的协议头,再发送给下一层。
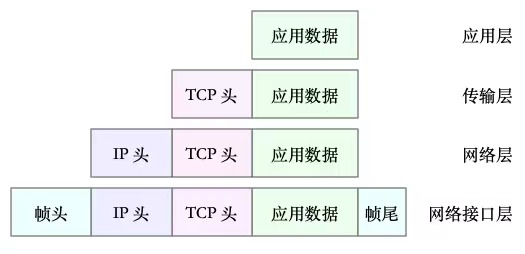
例如应用层发出的json数据,到达传输层,会加上TCP头;封装后到达网络层,加上IP头;最后到达网络接口层,在IP数据包的前后按照特定的协议格式分别加上帧头和帧尾。
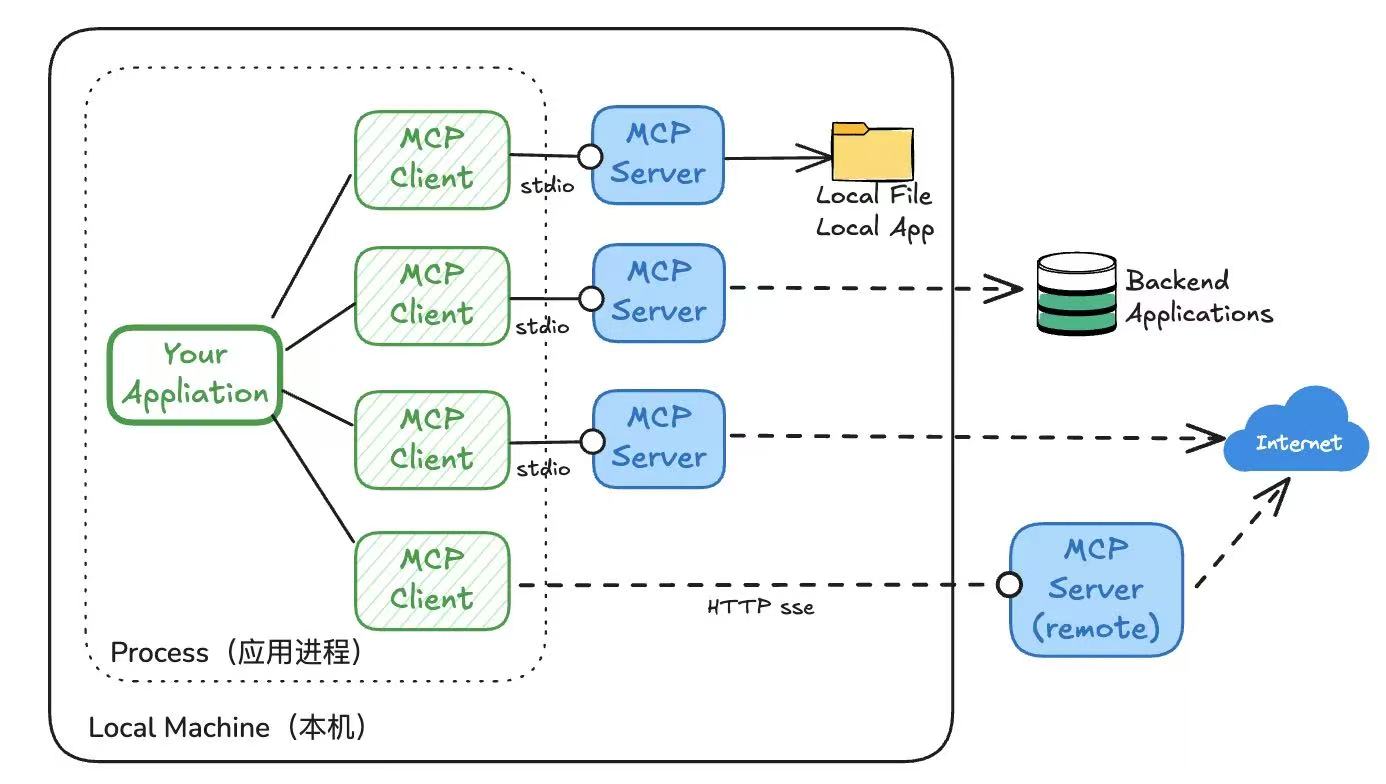
对应到Linux内核,其网络栈模型和TCP/IP四层模型比较类似,如下,Linux通用IP网络栈的示意图:
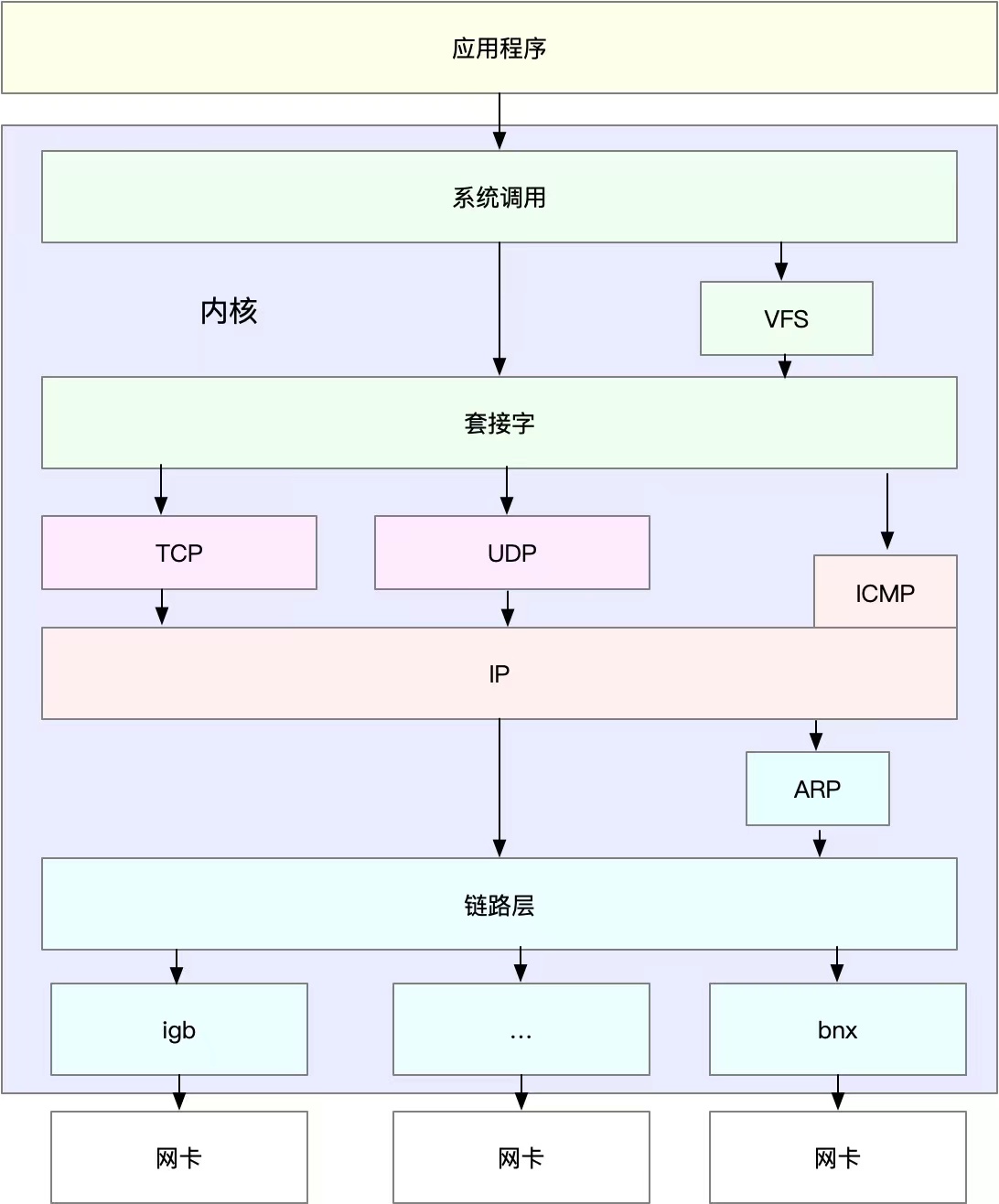
可以看到:
- 最上层的应用程序通过系统调用(用户态到内核态)与socket套接字交互
- 套接字下面对应到传输层、网络层
- 网络层下面对应着网络接口层,包括图中链路层和最后的网卡
图中名词说明:
1、igb、bnx等可以理解为网卡的驱动程序
2、VFS表示虚拟文件系统,底层各类文件的抽象,给上层提供文件访问接口
3、网卡是发送和接收网络包的基本设备。系统启动时,通过内核中网卡驱动程序注册到系统中。
网路包收发流程
网络包接收过程
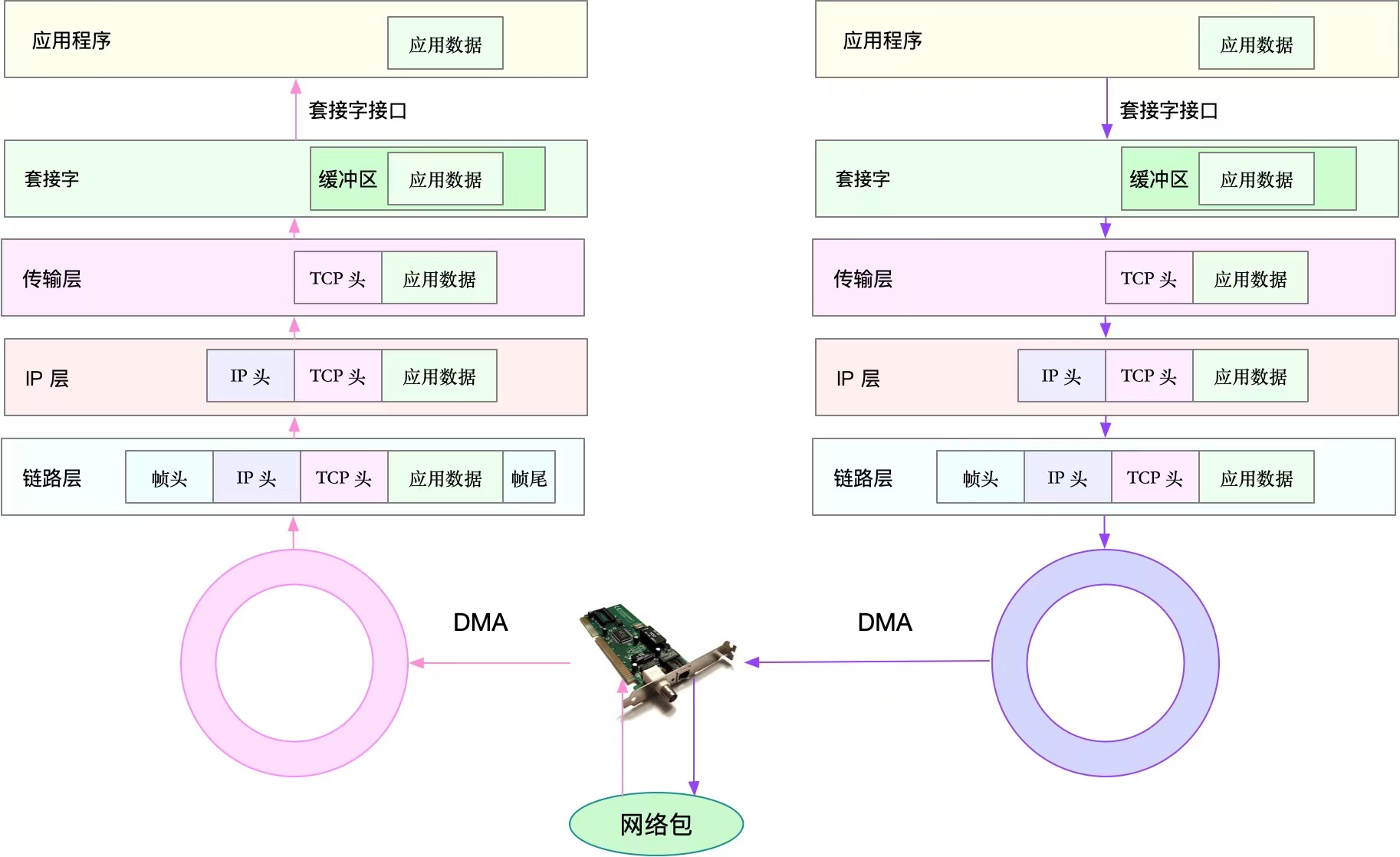
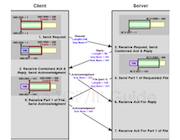
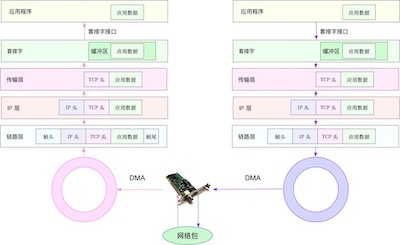
如图,红色箭头(左半边)表示网络包接收过程:
- 网络包首先到达网卡,网卡通过DMA的方式(DMA具体下面会介绍)将数据拷贝到接收队列,即图中的圈,也叫Ring Buffer。
- 然后DMA通过硬中断告诉系统,系统中的中断处理程序分配sk_buff,将Ring Buffer中的数据包拷贝到sk_buff缓冲区。
- 然后中断处理程序触发软中断,内核开始处理sk_buff缓冲区数据,内核协议栈会从下层到上层逐层拆解分析该数据包:
1)、链路层检测报文的合法性,找出上层协议的类型(IPv4或者Ipv6),再去掉帧头和帧尾,交由网络层;
2)、网络层取出IP,判断报文走向,如果是发给当前主机的,取出IP头,交由上层传输层,否则丢掉此报;
3)、报文到达传输层,取出TCP或UDP的头,根据四元组(源ip、源端口、目标ip、目标端口)找到对应的Socket标识,将数据拷贝到Socket缓冲区(内核空间)。 - 最后,应用程序通过socket接口(系统调用)完成数据的接收,从Socket缓冲区拷贝到应用程序缓冲区,在应用进程缓冲区进行操作数据。
网络包的发送如图右半部分:
- 首先,应用程序调用socket接口,这是一个系统调用,CPU会有上下文切换,从用户空间到内核空间,将数据放到Socket发送缓冲区。(此时调用线程便会返回,至于包什么时候发出,有网络协议栈决定。)
- 然后,网络协议栈从Socket缓冲区中取出数据包,再按照TPC/IP栈,从上到下进行逐层处理(如增加协议头、路由查询确认下一跳、按MTU拆包等)。
- 分片后的网络包,到网络接口层,进行物理寻址,找到下一跳的MAC地址,添加帧头和尾,拷贝到发送队列(Ring Buffer)。
- 最后,驱动程序通知DMA,从发送队列中读取网络帧,并通过物理网卡发送出去。
扩展说明
1、套接字缓冲区:也即Socket缓冲区,是应用程序通过socket接口进行操作的内核空间缓冲区。
2、sk_buff:是一种表示报文的数据结构,各层协议都依赖于sk_buff。在各层进行处理的时候,并不会进行数据的拷贝,而是通过操作该数据结构中的指针完成。(如果把内核网络协议栈比作一个人,那么 sk_buff 就是流淌在他体内血管里红血球,它运输养分(数据)走遍全身(协议栈每一层))
3、Ring Buffer:也即环形缓冲区或文中提到的队列,它是由系统启动时,初始化网卡(NIC (network interface card) ),系统分配的内存空间。网卡可以通过DMA技术进行操作的内存空间。(网卡启动的同时也会向内核注册一个硬中断处理函数)
4、DMA:DMA(直接内存访问,Direct Memory Access)是一种数据传输技术,允许外设(如网卡、磁盘控制器、显卡等)直接访问计算机内存,无需经过CPU。通过DMA技术可以大大提高数据传输的效率,减轻CPU的负担。
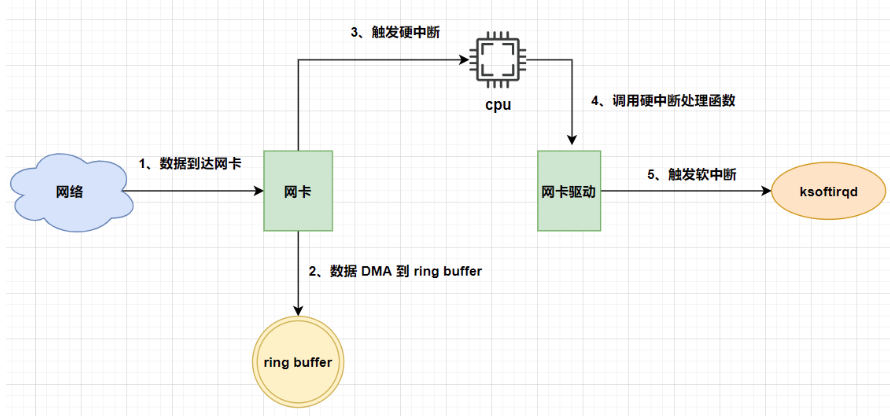
如图,网卡使用DMA完成数据拷贝过程:
- 首先,网络包到达网卡,网卡包括混杂和非混杂两种模式(混杂模式接收所有数据包;非混杂模式校验Mac地址,只接受发给本机数据包);网卡会将数据包的内容缓存在硬件缓冲区中。
- 网卡通过DMA的方式,将收到的数据从硬件缓冲区输入到系统内存Ring Buffer中,该过程不需要CPU参与。
- 当数据包到达Ring Buffer后,会触发硬中断,告诉CPU数据包已经到了。
触发中断的时机,有如下参数控制(查看命令:ethtool -c 网卡):
1)、rx- usercs:多长时间后会触发一个硬中断
2)、rx-frames:累计接收多少数据帧后,触发一个硬中断 - CPU收到硬中断命令后,会停下手中的活,保存上下文,然后调用网络驱动注册的硬中断处理函数,做一些简单的记录,随即调用软中断
- 软中断处理线程执行,为数据包分配sk_buff内存,并将数据拷贝到sk_buff缓冲区。随后网络协议栈逐层进行处理。
总结
通过本文能有个大概的Linux对接收网络包的处理过程:
1、首先先到网卡
2、网关配合DMA完成网络包到Ring Buffer的拷贝,这里是内存区域
3、DMA触发硬中断,CPU响应调用网卡启动时注册的硬中断处理函数
4、硬中断处理函数基本没做什么,就发起了软中断请求
5、软中断请求由内核线程ksoftirqd线程进行处理
6、将Ring Buffer中的数据拷贝到sk_buff缓冲区,进行逐层解析网络数据,在传输层找到对应的Socket,将数据拷贝到对应的Socket缓冲区
7、最后,由应用程序通过系统调用Socket接口完成数据访问