TCP协议之拥塞控制
前言
有了滑动窗口的流控,为什么还需要拥塞控制呢?前面关于TCP滑动窗口的文章介绍了如何通过接收方窗口大小控制发送方窗口大小,以此来达到流控的目的,它对应的是TCP协议层的事情。对于网络的拥塞情况是无法得知的,如果出现共用网络环境(基本上是),就不能忽视“网络”的情况,不然会出现延时、丢包等情况,甚至加重网络延迟,导致网络瘫痪。
所以TCP要避免这种事情,当拥塞发生时,TCP自我牺牲,降低发送的数据量。
于是,就有了拥塞控制,目的就是避免“发送方”把网络压垮了。
拥塞窗口
在拥塞控制算法中,有个概念叫拥塞窗口(Congestion Window,简称cwnd),它和发送窗口(SND.WND)又有什么区别呢?
拥塞窗口
拥塞窗口(cwnd)是TCP拥塞控制的一个变量,发送方维护,它代表发送方基于自身对网络状况的评估而决定可以发送的最大数据量。
发送窗口一般约等于(时间差)接收窗口大小,在加入拥塞窗口的概念后,发送窗口大小=min(cwnd, RCV.WND),也即拥塞窗口和接收窗口的最小值。
发送窗口
发送窗口(SND.WND)是TCP流控的一个变量,也表示了接收方最大能接收的数据量,由接收方缓冲区大小和数据消费速度决定。
拥塞控制算法
拥塞窗口(cwnd)的变化规则:
- 网络拥塞时,cwnd减少
- 网络不拥塞时,cwnd增加
如何判断网络是否拥塞呢?只要发生了超时重传或者快速重传时,便认为网络出现了拥塞或者丢包情况。
拥塞控制主要包括了四个算法:
- 慢启动
- 拥塞避免
- 拥塞发生
- 快速恢复
这四个算法一直在更新优化中。
1988年TCP Tahoe提出了慢启动、拥塞避免、拥塞发生时快速重传;
1990年,TCP Reno在Tahoe的基础上增加了快速恢复算法,并在1995年提出TCP new Reno改进了快速恢复算法。
慢启动
当连接建立后,一点点提高发送数据量,在没有摸清网络拥塞情况下,谨慎发送数据。
慢启动的算法如下:
1)、连接建立好后,先初始化cwnd=1 * MSS,1表明传输一个MSS大小的数据(cwnd值表示具体的字节数据)。
2.1)、每收到一个ACK后,cwnd = cwnd + 1 * MSS,于是第二次发送 2 个 MSS的数据。
2.1.2)、分别收到2个MSS的数据的ACK后,即2个ACK,cwnd再加2 * MSS,于是下次可发送4个MSS。
2.2)、每过1个RTT,cwnd = cwnd * 2,即 cwnd = 1MSS * (2^RTT次数),对RTT的次数来说,是指数型增长。
2.1)和2.2)可以只考虑一个进行理解增长即可,说的是一个事。
3)、cwnd不能无限制的增加,所以有个阈值门槛,一旦超过便不会再指数型增长,而是进入下一步进行拥塞避免算法,这个阈值叫ssthresh(slow start threshold)。
慢启动的图示如下所示(注意第2个图的横坐标是RTT的次数,即时间):
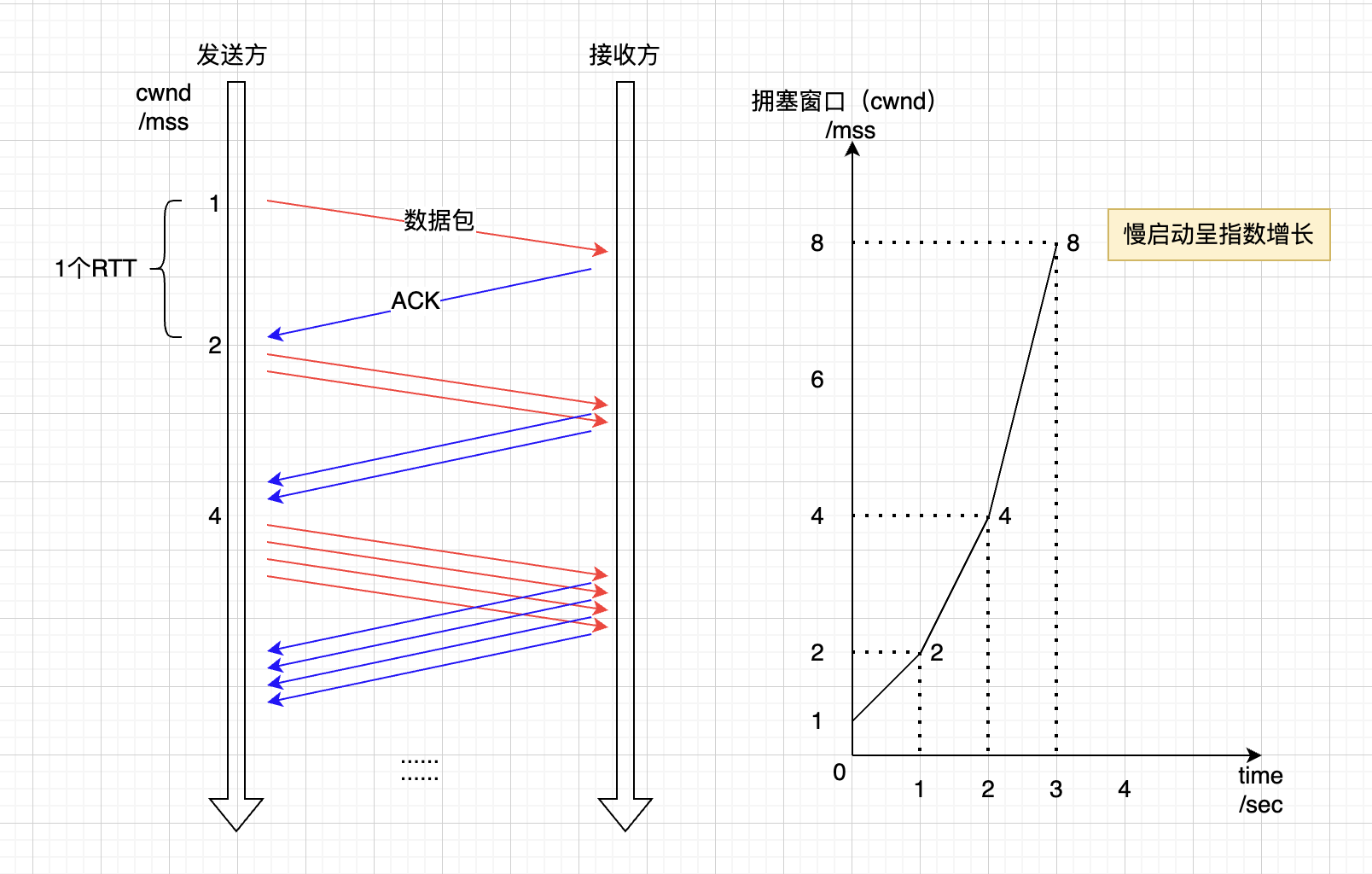
指数增长的慢启动,其实并不慢,直到增长到ssthresh
再补充下:
1、在TCP实现中,据2009年起草的RFC 5681记录,cwnd的初始值由MSS影响:
- 当 MSS <= 1095 bytes,
cwnd初始化为:4 * MSS - 当 MSS >= 2190 bytes,
cwnd初始化为:2 * MSS - 当 1095 bytes < MSS < 2190 bytes,
cwnd初始值为:3 * MSS
现在网络环境更好了,初始值可能更大了。如2010年google论文中建议cwnd初始值为10 * MSS。
不同的Linux版本有不同的cwnd初始值实现。
2、慢启动上限阈值ssthresh的值设置的相对高一些,通常为滑动窗口的最大可能大小(65535字节),这个为了让网络的实际情况决定数据的发送速率,当出现网络拥塞时,必须降低ssthresh的值。
ssthresh在拥塞时降低,理论上,可以减少到1个MSS大小,这样会严重影响传输效率;且ssthresh一般不会主动增加,它在拥塞发生时降为较小值,然后保持不变直到下一次拥塞出现。可能在一些特殊的实现中,有一些规则用来调整ssthresh的值。
拥塞避免
当慢启动增长到ssthresh时,便会使用拥塞避免算法。
上面提到ssthresh设置尽量高一些,一般来说有65535字节,当cwnd达到这个值后,算法如下:
1)、收到一个ACK后,cwnd = cwnd + (1 * MSS)/cwnd;
即大概经过一个RTT时间后,cwnd = cwnd + 1 * MSS。
假设上面慢启动的ssthresh为8 * MSS,8个MSS数据发出后,那么8个包的ack收到后,cwnd变成9(8 + 8 * 1/8)。
所以,拥塞避免下,cwnd是线性增长。
拥塞发生
经过了拥塞避免,慢慢网络达到饱和,就可能出现丢包重传的现象,这时候就是拥塞发生了。
对于数据重传,有两种处理方式:
- 超时重传(超过RTO时间)
- 快速重传(收到3次重复的ACK)
1、对于超时重传
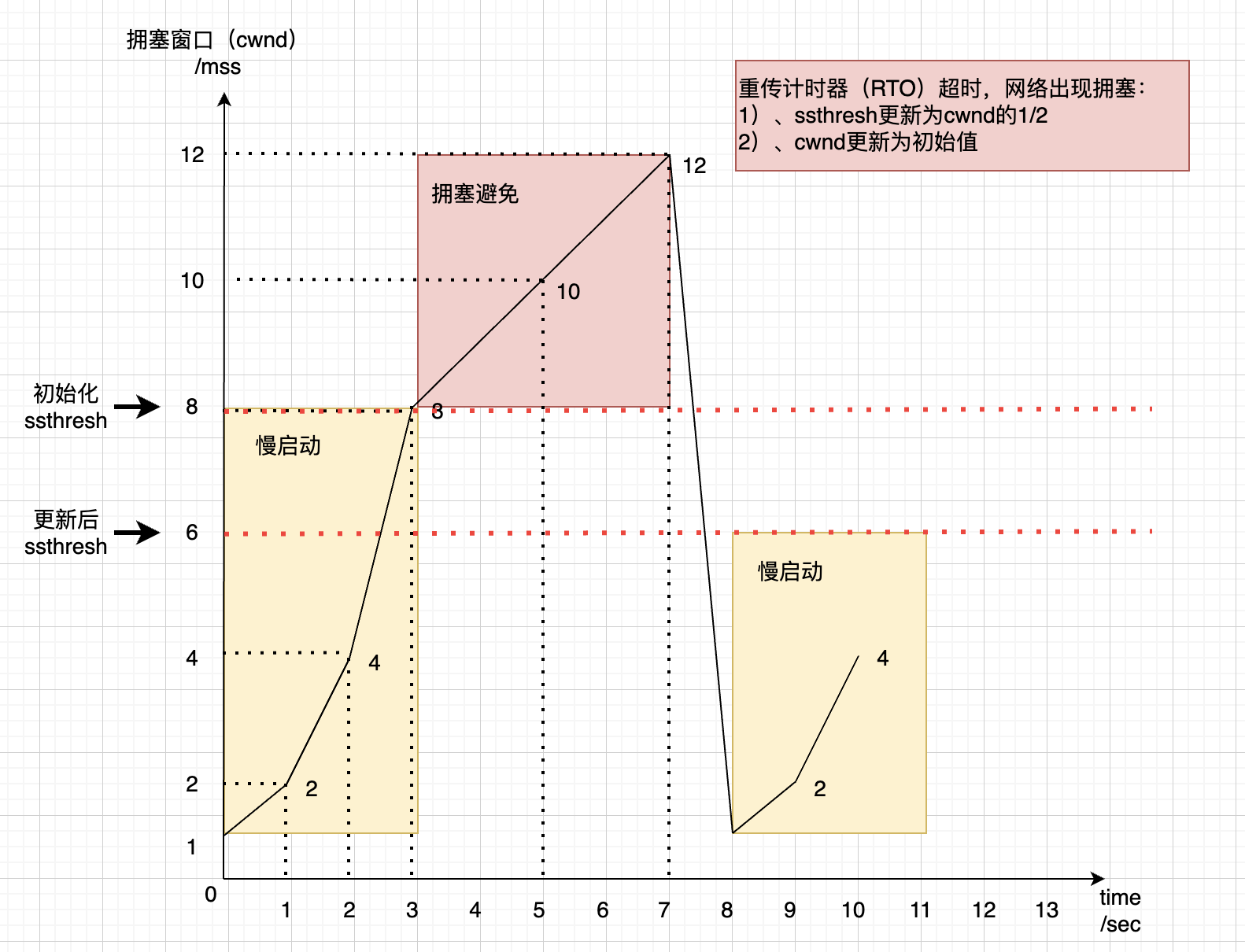
出现超时重传时,TCP认为这种情况比较严重,会处理的更果断些,算法如下:
1)、ssthresh变成1/2 * cwnd
2)、cwnd变成初始化时的值为1 * MSS。(本文假设的1 * MSS)
3)、进入慢启动过程
图示如下所示:
Q:Linux如何查看cwnd的初始值?
A:使用Linux的 ss -nli | grep cwnd 命令;输出示例如下:cubic cwnd:10,表示10个MSS大小。
2、对于快速重传
出现3个重复ACK时,不用等到RTO超时,便会进行重传。
- TCP Tahoe的实现和RTO超时一样。
- TCP Reno的实现算法如下:
1)、cwnd先变成原来的1/2
2)、ssthresh=cwnd(也即减半)
3)、进入快速恢复算法
不管哪种重传方式出现,ssthresh都是等于cwnd的1/2。
快速恢复
快速恢复算法是和快速重传一起使用的,当出现快速重传时,认为网络还没那么糟糕,所以在进行了拥塞窗口的调整后,进入快速恢复。
TCP Reno
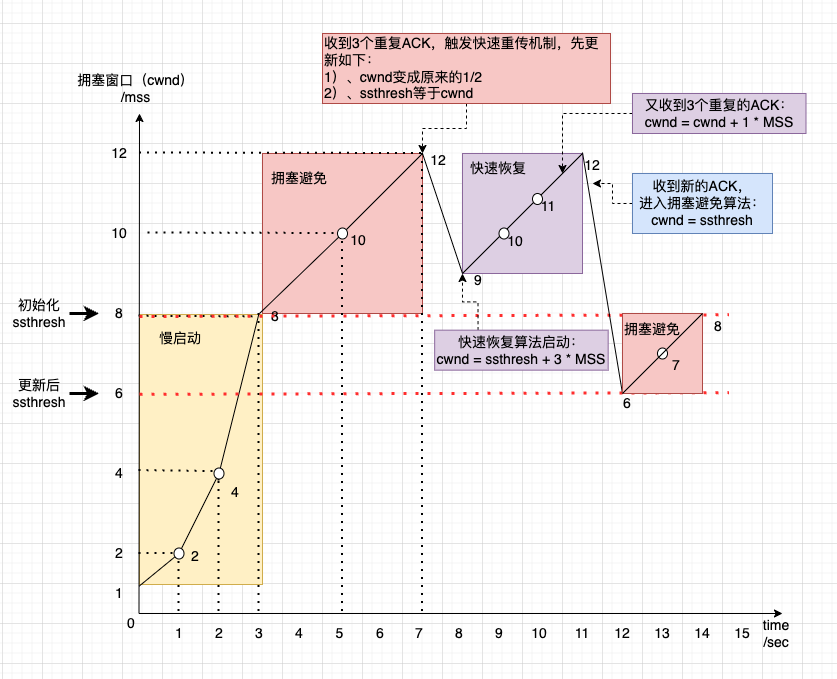
首先在拥塞发生时,更新了cwnd和ssthresh的值(见拥塞发生时快速重传情况)。
1)、cwnd先变成原来的1/2
2)、ssthresh = cwnd(也即cwnd减半)
然后,真正的快速恢复算法,如下:
1)、cwnd = ssthresh + 3 * MSS(3表示确认有3个数据包被收到了,ssthresh已经被修改为cwnd的一半)
2)、重传重复ACK的数据包
3.1)、如果再收到重复的ACK,那么从cwnd = cwnd + 1 * MSS
3.2)、如果收到新数据的ACK后,把cwnd设置成ssthresh,进入拥塞避免算法。
图示过程如下所示:
这里算法有个问题是:对于3个重复的ACK,发送方收到后并不知道还有哪些数据接收方也没收到,那么后面没收到的数据只能超时或者一起发过去(一起发会导致网络拥塞加重)。此时有SACK和D-SACK可以知道有哪些数据已经收到了,方便发送方决策,但是并不是所有的操作系统都实现了SACK,所以需要一个没有SACK的解决方案,往下看TCP New Reno算法。
TCP New Reno
在1995年,TCP New Reno算法被提出,主要针对没有SACK机制时的快速恢复算法。
参考RFC 6582
算法如下:
1)、当发送方收到3个重复的ACK后,进入快速重传,重传丢的那一个包,如果只有1个包丢了,重传回来的ACK会把整个已经发送的数据都ACK了;否则说明丢了多个包,这种情况下这个回来的ACK叫做Partial ACK。
2)、一旦Sender发现了Partial ACK出现,那么就可以确认是出现多个包丢了,于是继续重传滑动窗口中未被ACK的第一个包,也即SND.UNA对应的位置,直到收不到Partial ACK,即所有发送数据包均被ACK,此时结束快速恢复过程。
可以看出来,这个算法过程,会延长快速重传和快速恢复的过程。
更多算法
2023年8月,基于RFC 5681,改进或调整了算法见RFC 9438:CUBIC for Fast and Long-Distance Networks。
CUBIC表示使用立方增长函数来调整拥塞窗口(cwnd),它是一种流行的TCP拥塞控制算法,目前在新的Linux版本中,使用了CUBIC相关算法,它适用于高带宽和高延迟的网络环境,如长距离的网络连接。
还有很多其它的算法,后面有机会再一一揭秘:
- TCP Vegas算法:1994年被提出,它通过估计网络吞吐量来提前监测和预防网络拥塞情况,算法论文地址>
- HSTCP(High Speed TCP):为高带宽和长延迟设计的拥塞控制算法,来自RFC 3649
- TCP BIC算法:2004年提出,Binary Increase Congestion (BIC) TCP 是一种为高速网络环境设计的拥塞控制算法。BIC 使用一种二分查找策略来快速找到最佳的窗口大小,然后小心地调整窗口以避免拥塞。相关新闻Google《美科学家研发BIC-TCP协议 速度是DSL六千倍》
- 更多见Wikipedia地址>
总结
为了进行网络环境的监测,有了拥塞控制算法,主要包括了慢启动、拥塞避免、拥塞发生、快速恢复四大步骤或场景,具体的实现至今仍在不断优化中。