关于ChatGPT
前言
源自《这就是ChatGPT》这本书,书内提到了一些人工智能的概念及ChatGPT的内部机制和原理,可以帮助我们更深层次的认知ChatPGT。文章也会围绕书中概念进行输出。
概念
什么是模型
书中提到假如你想知道从比萨斜塔各层掉落的炮弹分别需要多少时间,可以通过表格记录每种情况的测量结果,但你无法测量所有情况,所以需要建立一个“模型”,用它来完成计算。
假如理论上存在这么一种模型,但是如何得到它呢?
我们可能会做出数学上的猜测,假设它是一条直线,或者更复杂的数学模型,来使用测量数据进行拟合,最终形成一个函数或者算法并可以通过它来预测未知数据。ChatGPT-3.5就是这样一个拥有1750亿参数量的"大"模型。
例如:
分类模型:判断一张图片上是猫还是狗
回归模型:预测票房和股价
生成模型:生成新的文本、图像和音乐
一次只添加一个词
我们知道大模型问答就像打印机一样,逐字输出,即每次只预测下一个最可能的词,直到生成完整的句子,它是结合了数十亿个网页上的内容,结合原始输入预测出预期的输出。
当然,一句话的下一个词,不太可能只有某一个固定的词,它可以有多种选择,这就涉及到概率问题,应该选择何种概率,就如同相同的问题,会有不同的输出一样,在ChatGPT里面,有一个专门的参数“温度”用来控制,值是从0到1,值越大,随机的概率就越高,相同的问题,就越有可能不一样。
神经网络
用于图像识别等任务的典型模型是使用神经网络,它被发明于20世纪40年代。神经网络可以被视为对大脑工作机制的简单理想化,人类有1000亿个神经元(神经细胞),每个神经元都可以产生电脉冲,最高每秒约1000次,每个神经元又可以和其它数千个神经元传递电信号,从而连接成复杂的神经网络。
神经网络在结构上,通过多层组成,通常包括输入层、隐藏层和输出层,每一层由多个神经元构成,神经元之间通过权重连接。ChatGPT-3.5的175B参数量,主要指的就是模型中的权重和偏置,权重是连接两个神经元的参数,决定上个神经元对下个神经元的影响程度;偏置是添加到每个神经元输出中的参数,用于调整激活函数,改善模型的性能。
例如 z=ax + b,a表示权重,x为输入,b表示偏置,输出a = g(z), g表示激活函数,最终输出a。
激活函数
激活函数是作用于神经元输入-输出映射的数学函数,主要作用是引入非线性,是神经网络能够学习和表示复杂的非线性关系,不同的激活函数具有不同的特性。因此,在不同的层中可以根据任务需求选择合适的激活函数。
常见激活函数包括:ReLU(Rectified Linear Unit)、Sigmoid、Tanh(双曲正切)、Leaky ReLU、Softmax。
模型预训练
模型通过大量文本进行预训练,为了让模型学习到语言的基本规律和知识,为后续任务提供基础。GPT系列就是通过在预训练阶段预测下一个词来学习语言的规律,首先根据前文预测下一个词的概率,模型将预测的概率分布和真实的词(即训练数据中的下一个词)进行对比,计算出损失函数,损失函数是衡量模型预测的概率分布与真实分布的差异。最后通过反向传播,不断调整内部参数来减少损失函数的值,减少预测误差,提高模型性能。
预训练方法包括自监督学习、监督学习、无监督学习等。
参数微调
参数微调(Fine-tuning)是指在预训练模型的基础上,通过调整部分或全部模型参数,使其适应特定任务或领域的技术。预训练模型(如GPT)在大量通用数据上训练后,具备了广泛的知识和语言理解能力,但在特定任务上可能表现不佳。通过微调,可以在保留预训练模型核心能力的同时,使其更专注于特定任务。
拟合
拟合是指模型通过学习训练数据,找到数据中的规律,并能对新数据进行预测。
欠拟合:模型参数较少,无法捕捉数据中的规律,在训练集和测试集上都表现不佳。需要提供模型参数、提高数据质量等方式解决。
过拟合:模型过度训练了数据的噪音和细节,在训练集数据上表现良好,但是测试集上表现较差。需要简化模型、提高数据质量、减少训练时长等方式解决。
Transformer
Transformer是一种基于自注意力机制的深度学习框架,主要用于处理序列数据,如自然语言处理(NLP)任务。
它是Google在2017年的论文《Attention is All You Need》中提出,核心思想是通过自注意力机制取代传统的循环神经网络(RNN)结构实现并行计算和全局信息捕获。
架构图如下:
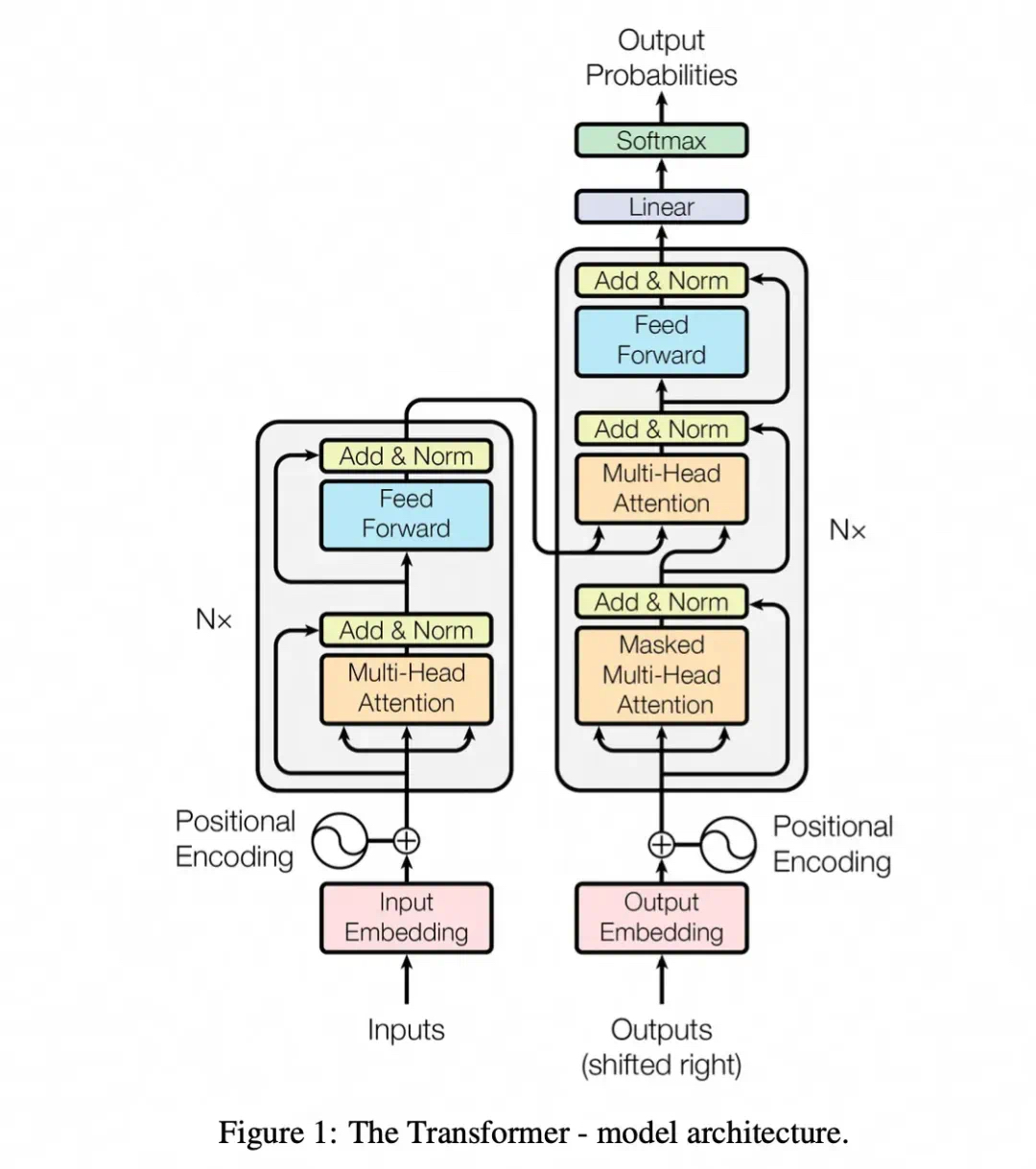
Transformer通常包括:
1、输入嵌入(Embedding):将输入序列(如文本)转换为向量。
2、位置编码(Positional Encoding):为输入序列添加位置信息,以弥补Transformer缺乏顺序处理能力的不足。
3、编码器处理:通过多层编码器对输入序列进行编码,生成上下文相关的隐藏表示。
4、解码器处理:解码器根据编码器的输出和已生成的部分目标序列,逐步生成完整的输出序列。
5、输出生成:通过线性变换和Softmax函数,生成最终的概率分布,用于预测下一个词或字符。
ChatGPT工作原理
ChatGPT是基于Transformer架构的生成式预训练模型(GPT),其核心是使用Transformer的解码器部分进行文本生成。
1、预训练:ChatGPT使用大量文本进行训练,学习语言模式和上下文关系。训练过程中,通过自回归方式预测下一个词,逐步优化参数。
2、微调:在特定任务对话上对预训练模型进行微调,使其适应特定应用场景。
3、推理:在用户输入问题或指令后,ChatGPT通过Transformer解码器生成响应。模型根据输入文本的上下文逐步预测下一个词,直到生成完整的回答。
总结
总的来说,ChatGPT 通过预训练和微调的结合,具备了强大的语言理解和生成能力,广泛应用于对话系统、文本生成、问答系统等领域。