RAG-检索增强生成
前言
一方面AI训练成本烧钱且耗时,ChatGPT-4训练成本大概有1亿美元,持续至少6月以上;
另一方面数据是静态的,对于如天气、时间等实时数据无法感知。
最后,对一些垂直领域企业,数据是私有化的,通用大模型回答效果会差一些。
所以,就有了外部数据和LLM结合的技术-RAG,在问大模型前,先通过搜索知识库,拿到结果后连同问题一起提供给大模型进行咨询。
你可能会问,可以在模型的基础上进行微调,但微调数据也是静态的,且需要我们自行部署模型来微调,以此达到相对实时且安全的要求,这又是成本和收益的权衡了。
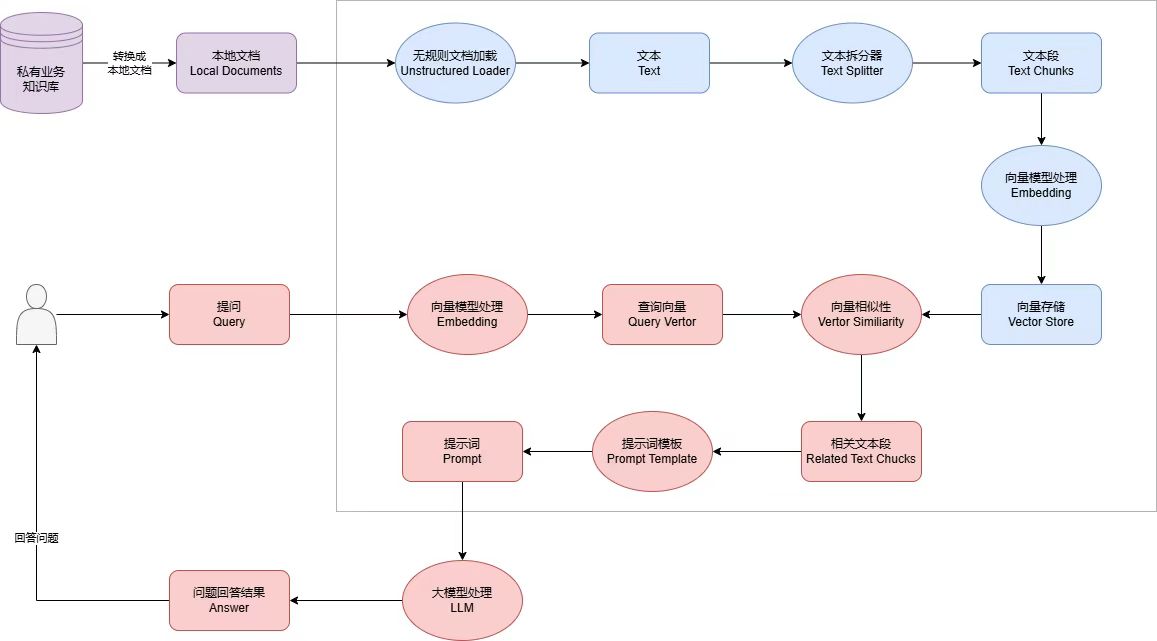
RAG的流程
RAG(Retrieval Augmented Generation 检索增强生成):是一种结合了信息检索和文本生成的AI模型框架,它通过从外部知识库中检索相关文档来增强生成内容的准确性和丰富性。
先看下RAG的流程图:
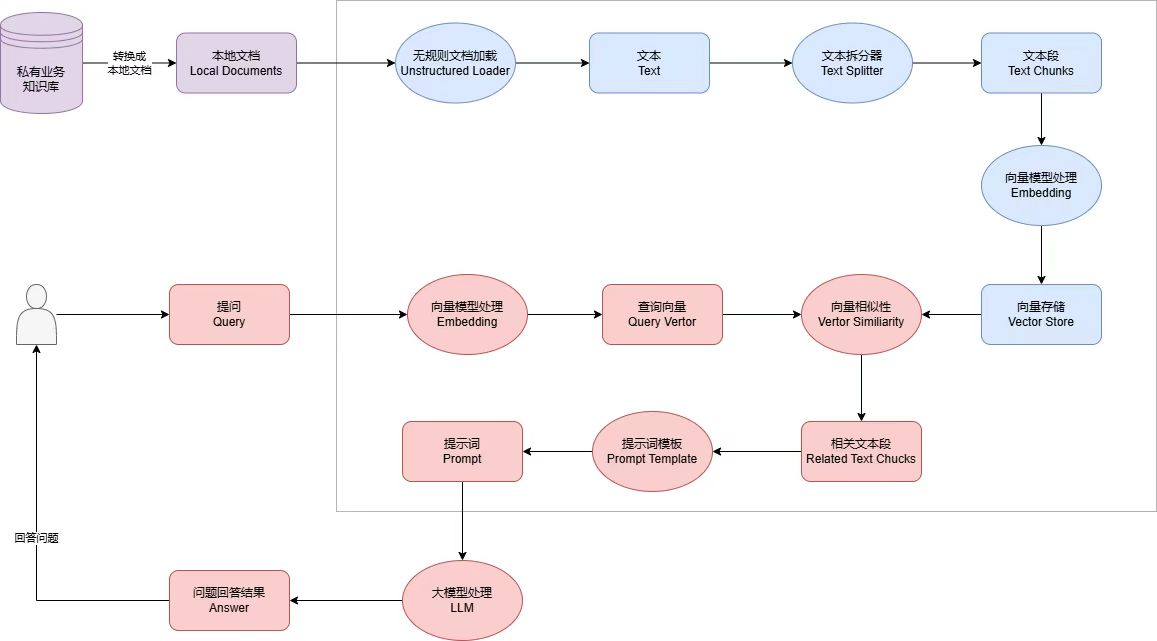
步骤如下:
1、将私有业务知识库的内容,提取文字并进行分段处理。
2、将分段好的文本内容向量化,并存储到向量数据库。
3、用户提问并对问题进行向量化,与向量数据库的内容做相似性对比,找出匹配的文本段落。
4、通过Prompt Template对内容进行整理并产生最终的Prompt。
5、将最终的Prompt交给LLM大模型语言,LLM返回问题的答案。
步骤中提到的向量化,后面会单独介绍,向量化就是通过将文本、语音等内容根据其特征进行多纬度向量化并存储,方便根据语义检索。存储一般会使用向量数据库,如es、pg、weaviate、qdrant、milvus、zilliz 、milvus 、myscale等等。
RAG和SFT的区别
SFT(Supervised Fine-Tuning)监督微调,是指在机器学习和自然语言处理(NLP)领域,代表一种训练模型的方法,通常在预处理模型(如GPT)的基础上,使用标注数据对模型进一步的训练,以使其更好的适应特定任务(如文本分类等)。
那RAG和SFT有什么区别呢?
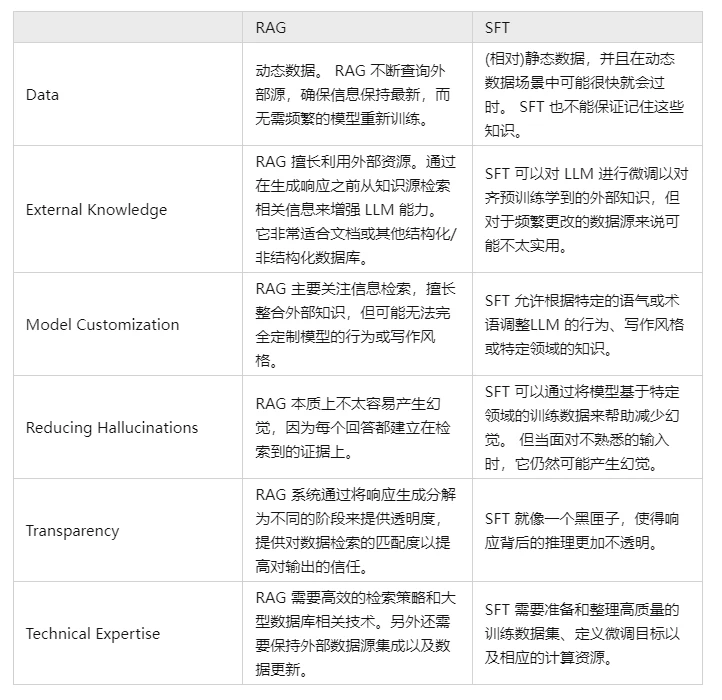
最主要的差异包括两点:
1、数据是否是动态,RAG的数据可以实时更新;SFT数据相对静态,新增就需要重新微调模型。
2、RAG擅长检索外部知识与模型形成联动;SFT可以做到改变模型的风格、行为及特定领域知识。
总结
平时使用RAG还是SFT或者通用模型主要还是结合使用场景、使用门槛、资源情况等来选型。
常见的包含知识库的AI应用开发平台有:Dify、Coze、FastGPT等。