mysql索引下之索引使用与分析
前言
确定了mysql InnoDB引擎使用B+树索引结构后,那如何使用好索引加快查询速度呢?接下来展开介绍下。
索引的语法
创建索引的时机有两种,一种是创建表时创建索引,另一种是创建表后在某时间新建索引。
DDL创建索引示例:
1、创建表时创建idx_user_id二级索引
CREATE TABLE `orders` (
`id` INT NOT NULL AUTO_INCREMENT COMMENT '主键id',
`order_name` VARCHAR(45) NOT NULL DEFAULT '' COMMENT '订单名称',
`user_id` INT NOT NULL DEFAULT 0 COMMENT '用户id',
`create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '时间',
PRIMARY KEY (`id`),
INDEX `idx_user_id` (`user_id` ASC)
) engine = InnoDB;
2、创建表后idx_user_id二级索引
alter table `orders` add index idx_user_id(user_id);
-- 或
create index idx_user_id on orders (user_id);
删除索引示例:
alter table `orders` drop index idx_user_id;
索引设计原则
针对设计原则,结合上面创建的orders介绍
最左前缀原则
新建联合索引:
alter table `orders` add index idx_user_id_name(user_id, order_name);
最左前缀原则,是说sql查询时如果是多列索引,那么查询条件需要包括最左侧列才能走该索引,如按user_id查询或按user_id加order_name查询时走索引,仅按order_name查询不会走索引。
走索引查询:
select * from orders where user_id = 1;
不走索引查询:
select * from orders where order_name = '彩电';
所以,在设计索引时,尽可能最大化索引的利用。
覆盖索引&回表
因为mysql的InnoDB是索引组织的表,主键索引的叶子节点包括了全部数据,当sql查询使用到了二级索引时,如果查询的数据列不全在建二级索引涵盖的列中,那么会回到主键索引中查询需要的数据,该动作为回表查询。
为了避免回表查询,增加查询速度,便有了覆盖索引的概念,即查询列全部在二级索引中。
如创建的二级索引 idx_user_id_name(user_id, order_name);
当使用如下sql查询时,不会产生回表查询:
select id, user_id, order_name from orders where user_id = 1;
其中id为二级索引的叶子数据,所以也不需要回表。
索引下推
是由mysql5.6引入的索引下推机制,还是orders表,先清除所有索引,引入新联合索引(暂不考虑索引的合理性):
alter table `orders` add index idx_order_name_user(order_name, user_id);
有如下查询语句,order_name 模糊查询:
select * from orders where order_name like '彩电%' and user_id = 1;
在5.6版本前,索引列只有order_name有效,从找到“彩电”开始的第一条记录开始,回表查询其它列数据,此时user_id=1的判断在回表检索后判断过滤;
在5.6版本后,索引列同样order_name有效,在找到“彩电”开始的记录时,同时会判断user_id字段,将user_id不为1的数据行排除掉,大大减少回表的次数,从而提升查询速度。
这便是索引下推的机制。
索引执行分析
加入了索引后,如果sql使用索引,那么可以增加查询速度,如何查看sql执行走的哪个索引呢?如果sql查询比较慢,又如何排查原因来解决掉慢查询呢?除了看慢查日志,还可以借助Mysql提供了Explain关键词。
Explain 官方文档地址>
-- 在orders表的基础上,增加表order_items;同时创建idx_order_id二级索引
CREATE TABLE `order_items` (
`id` INT NOT NULL AUTO_INCREMENT COMMENT '主键id',
`order_id` INT NOT NULL DEFAULT 0 COMMENT '订单id',
`goods_id` INT NOT NULL DEFAULT 0 COMMENT '商品id',
`amount` decimal(10, 2) NOT NULL DEFAULT 0 COMMENT '价格',
`create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '时间',
PRIMARY KEY (`id`),
INDEX `idx_order_id` (`order_id`)
) engine = InnoDB;
一个简单的explain例子:
-- 命令行执行,\G换行展示
explain select * from orders where user_id = 1\G;
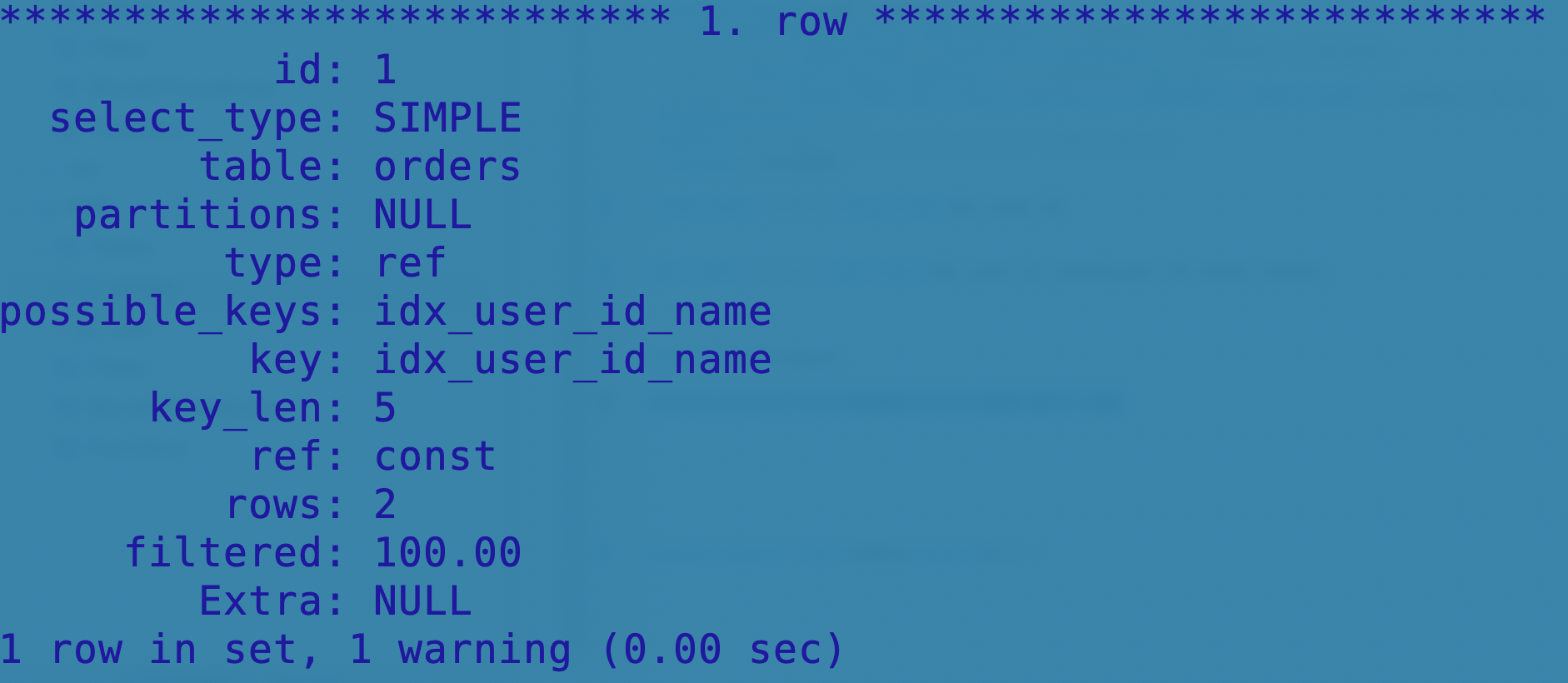
id列
标识select语句所属行编号(从出现select先后顺序,从1开始);如果没有子查询等复杂查询,那么id编号均为1。
select_type列
该列表示对应查询是简单还是复杂查询(子查询、派生表及union)
子查询:select (select * …) from …;
派生表:select * from (select …) as a;
union:select 1 union select 1;
常见值包括
1、SIMPLE:简单查询,查询不包括子查询和union;
2、PRIMART:如果查询有任何复杂查询,则最外层部分标记为PRIMART
3、SUBQUERY:对应包含在select 列表中的子查询中的select语句;
explain select o.*, (select amount from order_items limit 1) from orders o where o.id = 1;

4、DERIVED:表示包含在FROM子句中的子查询
explain select o.* from (select user_id from orders group by user_id) as o;

5、UNION:在union查询中,union关键词随后的select 被标记为union。
explain select 1 union select 1;

6、UNION RESULT:用来从UNION的匿名临时表检索结果的select被标记为UNION RESULT。
示例同5
table列
该列表示对应查询在查询哪个表。通常情况下展示比较清晰,值便是表名或者as的表别名。
对于其它复杂查询,需要匿名临时表时:
当在from子句中有子查询,table列是< deriverN>的形式,N为子查询的id列,总是“向前引用“。
当有union时,union result的table包括了参与union的id列表。union result所在id编号于参与union的id之后。
type列
该列表示mysql决定如果查找表中的行。
从最差到最优的值包括:ALL > index > rang > ref > eq_ref > const、system > NULL
1、ALL
表示全表扫描(例外情况,使用limit或Extra列显示Using distinct/not exist)
2、index
explain select user_id from orders as o;

index相对于ALL全表扫描,index是全索引扫描。
后面 Extra:Using index 表示Mysql使用覆盖索引,不用回表
3、range
范围扫描,比全索引好,不用遍历全部索引数据,一般sql中带有between或>或in等。
4、ref
一种索引访问(也叫索引查找),用于匹配某个单个值的查询,返回所有匹配单个值的行,当使用非唯一性索引时会发生。
-- user_id 索引列
explain select * from orders as o where user_id = 2;

5、eq_ref
使用这种索引查询,Mysql知道最多只会返回一条符合条件的记录。可以在Mysql使用主键或者唯一性索引查询时出现,性能比较好,因为它为在查到匹配行后无须再继续查找。
explain select * from orders as o, order_items i where o.id = i.order_id;

对于orders表,每一个order_items的order_id 在orders都是唯一的,所以对orders表,type为eq_ref类型。
6、const、system
如果是按数据的主键查询某一行数据的话,便会出现此类查询。
7、NULL
表示mysql在优化阶段分解语句,在执行阶段甚至用不到再访问表或索引。例如从索引列中查询最小值可以单独查询索引完成,不需要执行访问表。
-- user_id为索引
explain select min(user_id) from orders;
possible_keys 列
该列显示了查询可能使用哪些索引,即揭示哪些索引能有助于高效查询,基于查询的列与条件判断的,具体使用的索引需要key列。
key列
该列显示了Mysql最终决定使用哪个索引来优化对该表的查询。
key_len列
显示了Mysql在索引中使用的字节数;如果索引是联合索引,可以通过key_len计算出使用了哪些列。
同时,该key_len是表字段定义的长度,不是数据的长度。
rows列
该列展示了Mysql估计为了找到需要的行所读取的行数,不是Mysql从表里读取的真正的行数。
filtered列
显示的是符合查询条件的记录数的百分比的估算。
例如有些场景(表1000条数据,id<500查询)Mysql选择全表扫描,而不走索引,因为Mysql评估使用全表并不昂贵,因此,使用了全表扫描加where子句过滤,此时filtered便是一个估计的符合条件数据的百分比。
mysql5.1加入的
Extra列
额外展示的信息,不适合在其它列显示。
通常的值:
1、Using index
表示使用覆盖索引查询,select的列在索引中,不用回表查询。
注意:执行计划中的Extra列的“Using index”跟type列的“index”不要混淆。Extra列的“Using index”表示索引覆盖。而type列的“index”表示Full Index Scan(全索引扫描)。
2、Using where
表示Mysql服务器在存储引擎检索行后再在服务器层进行过滤,如下:
-- order_name非索引
explain select * from orders where order_name = '1';

如果查询索引时就能检验,便不会出现Using where,此处Null表示回表查询,如下:
-- user_id索引
explain select * from orders where user_id = 1;

3、Using where; Using index
是一种组合。
4、Using index condition
索引下推,是一种在存储引擎层使用索引过滤数据的一种优化方式。条件过滤索引再返回过滤到的数据。其仅用于二级索引场景,且是组合索引(左索引字段等于,由索引字段范围查)。
5、Using temporary
表示Mysql在对查询结果排序时会使用一个临时表。
6、Using filesort
表示Mysql会对结果使用一个外部索引排序,而不是按索引次序从表里面读取行。
Mysql有两种文件排序算法,两种算法都可以在内存或磁盘上排序,通过Using filesort 并不能看出来排序是在内存还是磁盘。
一般遇见filesort便可以考虑优化索引。
总结
索引使用需要遵循一定的原则,才能发挥索引的效果,设计原则包括
1、针对数据量量大,查询比较频繁的场景建立索引
2、考虑针对where、order、group进行操作的字段加索引
3、选择区分度高的字段进行增加索引
4、如果是字符串字段加索引,可以建立前缀索引,指定索引的长度,减少空间占用
5、尽量使用联合索引,同时考虑覆盖索引,减少回表
6、控制索引的数量,索引维护需要成本,也会影响增删改的速度
有了索引的加入后,再结合explain进行sql诊断,对于非预期的查询进行调整,以期达到比较优的查询速度。