mysql锁之行级锁
前言
上一篇介绍了关于mysql锁中的全局锁与表级锁。InnoDB同时支持了行级锁,为了更好的性能,更高的并发度。本篇主要介绍下Mysql InnoDB都有哪些行级锁以及如何锁记录的。
MyISAM不支持行级锁。相对于其它引擎,InnoDB支持事务、外键、行级锁。
文中演示均以Mysql8.0.31 版本,InnoDB引擎为例,使用8.0版本是因为它的锁信息查看替换为performance_schema.data_locks表。相比于5.7版本,使用的information_schema.innodb_lock表,5.7版本仅能看到锁竞争或阻塞的情况,8.0可以看到在非阻塞情况下的加锁信息。
Mysql8.0查看加锁语句:
select thread_id,object_name,index_name,lock_type,lock_mode,lock_status,lock_data from performance_schema.data_locks;
-- 初始化表结构与数据
CREATE TABLE `users` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`name` varchar(30) DEFAULT NULL COMMENT '姓名',
`age` int(11) DEFAULT NULL COMMENT '年龄',
PRIMARY KEY (`id`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户表';
INSERT INTO `test`.`users` (`name`, `age`) VALUES ('zhangsan', '21');
INSERT INTO `test`.`users` (`name`, `age`) VALUES ('lisi', '22');
INSERT INTO `test`.`users` (`name`, `age`) VALUES ('wangwu', '23');
INSERT INTO `test`.`users` (`name`, `age`) VALUES ('zhaoliu', '24');
INSERT INTO `test`.`users` (`name`, `age`) VALUES ('haha', '25');
INSERT INTO `test`.`users` (`name`, `age`) VALUES ('hehe', '21');
INSERT INTO `test`.`users` (`name`, `age`) VALUES ('heihei', '26');
INSERT INTO `test`.`users` (`name`, `age`) VALUES ('oo', '26');
INSERT INTO `test`.`users` (`name`, `age`) VALUES ('wowo', '9');
行级锁分类
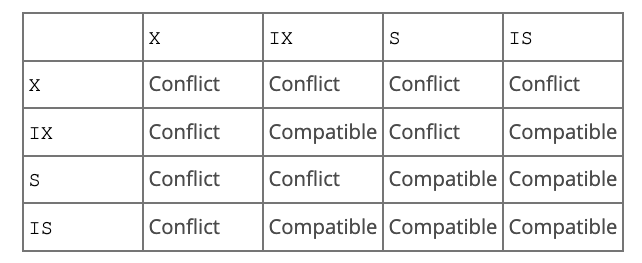
1、行锁(Record Lock):锁定单个行记录的锁,防止其它事务进行update、delete;在RC、RR隔离级别下支持。
2、间隙锁(Gap Lock):锁定索引记录间隙(不含记录),防止其它事务在该间隙insert,导致幻读;在RR隔离级别下支持。
3、临键锁(Next-Key Lock):行锁+间隙锁,同时锁住行记录与间隙,在RR隔离级别下支持。注意:Next-Key lock是前开后闭区间(即当前行及行之前的间隙)。
行锁
行锁包括共享锁(S)和排他锁(X)。
共享锁(S):一个事务获取到共享锁,允许其它事务获取共享锁,不允许获取排他锁;
排他锁(X):一个事务获取到排他锁,不允许其它事务获取共享和排他锁。
一个事务什么情况下会加共享锁或排他锁呢?
1、select正常查询:不加锁,使用的MVCC实现数据隔离(后面文章单独说);
2、 insert、update、delete:自动加排他锁;
3、select…lock in share mode:加共享锁;
4、select…for update:加排他锁。
当事务提交时,才会释放对应的锁。
原则
原则1、只要是行级锁,加锁的基本单位都是next-key lock
原则2、索引上的等值查询,如果是唯一索引加锁,则next-key lock退化为行锁
原则3、如果不通过索引进行检索,那么会对所有记录加锁,此时类似于升级为表锁。
演示1(退化为行锁)
有两个连接会话
1、会话1,开启事务,执行下面sql
-- 查询id为1的数据,手动加共享锁
select * from users where id = 1 lock in share mode;
查询加锁情况:

加的行锁,锁id=1这行记录
2、会话2,开启事务,执行下面sql
-- 查询id为1的数据,成功返回
select * from users where id = 1 lock in share mode;
查询加锁情况:
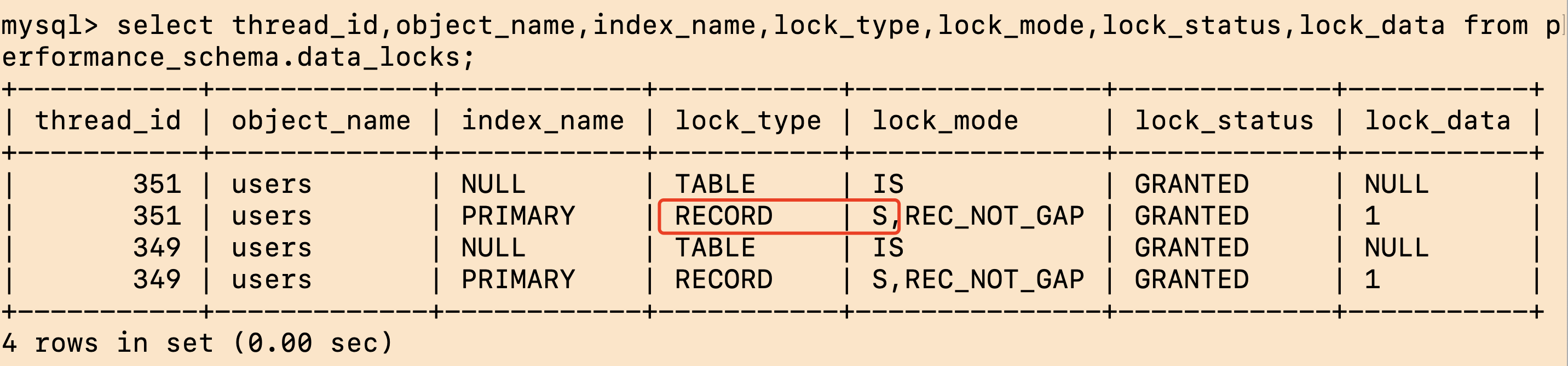
共享锁不互斥
3、会话2,commit提交后,重新执行如下sql
-- 更新id=1的age字段,出现阻塞
update users set age = 1 where id = 1;
查看加锁情况:
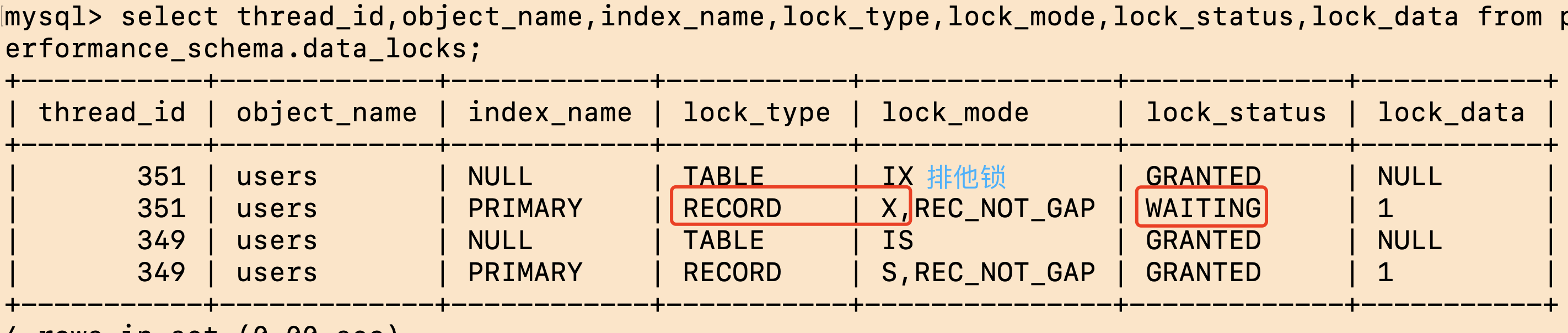
同样是行锁;共享锁与排他锁互斥
4、会话2,执行insert、update其它行记录,都能成功。
进一步说明临键锁退化为行锁
演示2(升级为表锁)
使用两个连接会话
1、会话1开启事务,执行如下sql
-- age不是索引
update users set age = 2 where age = 22;
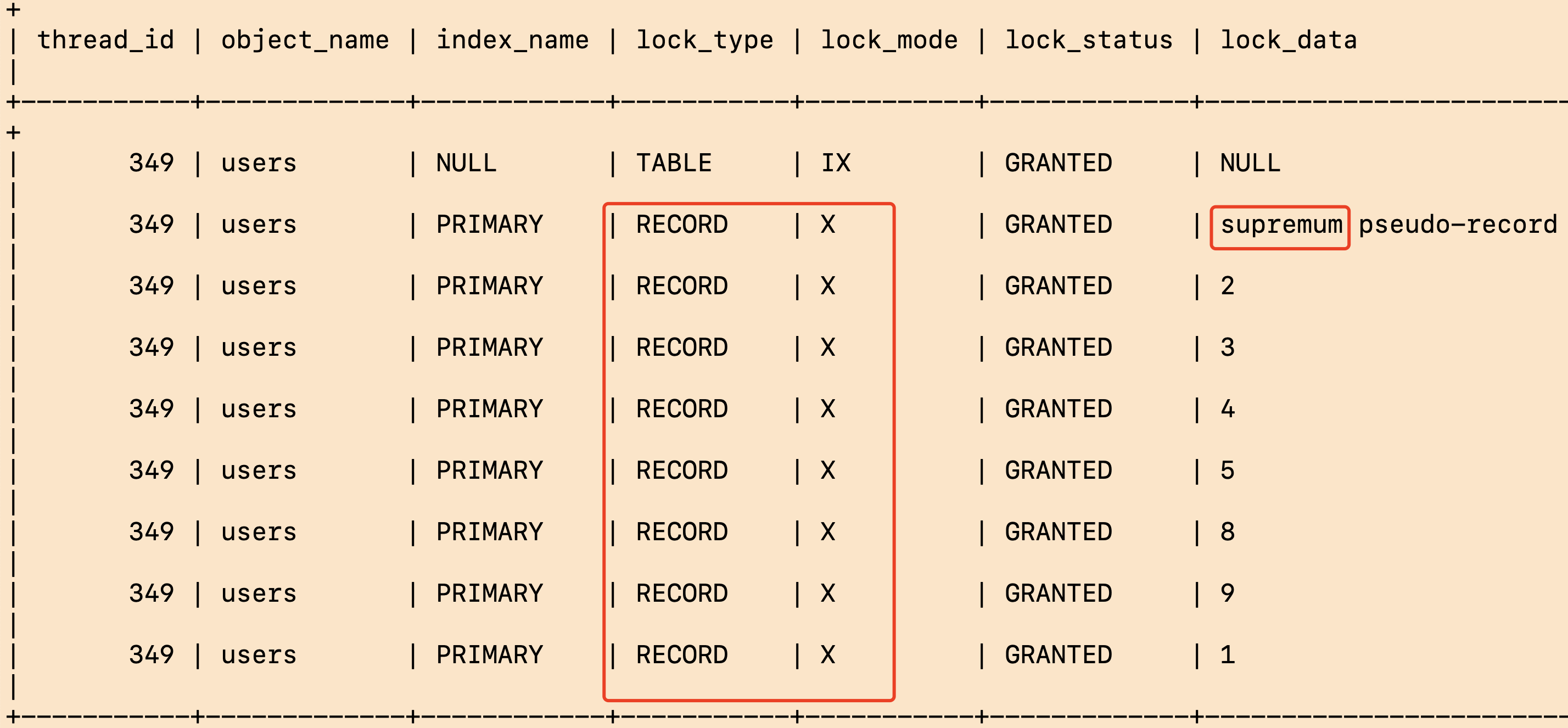
所有记录加锁;supremum pseudo-record表示最大值到无穷大范围
2、会话2开启事务,执行insert与update均阻塞
间隙锁&临键锁
间隙锁的目的是为了防止其它事务插入间隙数据。间隙锁可以共存,不互斥。
原则
原则1、索引上的等值查询,如果是唯一索引,给不存在的记录加锁时,优化为间隙锁。
原则2、索引上的等值查询,如果是普通索引,向右遍历时最后一个值不满足查询条件时,此时(最后一个值)的next-key lock退化为间隙锁。
原则3、唯一索引的范围查询(含等号)会访问到不满足条件的第一个值为止,加临键锁;
原则3补充:如果不含等号最后一个不满足条件的值会优化为间隙锁。(补充于2024-05-08)
-- 为了演示间隙锁和临键锁,清洗数据如下:
mysql> select * from users;
+----+----------+------+
| id | name | age |
+----+----------+------+
| 1 | zhangsan | 1 |
| 3 | wangwu | 3 |
| 5 | haha | 5 |
| 8 | oo | 8 |
| 9 | wowo | 9 |
+----+----------+------+
演示1(原则1)
两个连接会话
1、会话1,开启事务,执行sql
-- 不存在的唯一索引/主键查询
update users set age = 2 where id = 2;
此时加锁:

加锁id 1-3之间的间隙,不包括id=3
3、会话2,开启事务,执行间隙直接的插入
-- 阻塞,因为间隙锁
insert into users(id, name, age) values(2, 'hehe', 2);
4、会话2,开启事务,执行修改id=1和id=3的数据,均成功
mysql> update users set age = 11 where id = 1;
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> update users set age = 33 where id = 3;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
证明了原则1的正确性
会话1、2事务rollback,表数据不变,演示2。
演示2(原则2)
先添加age的普通索引:
alter table users add index idx_age(age);
两个连接会话,步骤如下:
1、会话1,开启事务,根据普通索引更新,执行如下sql
-- 成功
update users set name = 'wangwu2' where age = 3;
Query OK, 1 row affected (0.11 sec)
Rows matched: 1 Changed: 1 Warnings: 0
查看锁情况:

所以加锁为从1到5的间隙锁及3这个行锁,符合原则2。原则2中提到的此时优化为间隙锁指的是找到不满足条件最后一个值就是id=5这条记录,此时从3到5会优化为间隙锁。
2、会话2,进行更新与插入
-- 存在间隙锁,阻塞
insert into users(id, name, age) values(2, 'hehe', 2);
-- 执行成功
update users set age = 1 where id = 1;
update users set age = 1 where age = 1;
-- 因为是间隙锁,执行成功
update users set age = 5 where id = 5;
证明了原则2
rollback会话1,2,以便原数据演示原则3。
演示3(原则3)
使用两个连接会话
1、会话1,开启事务,执行如下加锁语句
-- 手动共享锁
select * from users where id >= 8 lock in share mode;
+----+------+------+
| id | name | age |
+----+------+------+
| 8 | oo | 8 |
| 9 | wowo | 9 |
+----+------+------+
2 rows in set (0.00 sec)
查看加锁语句:
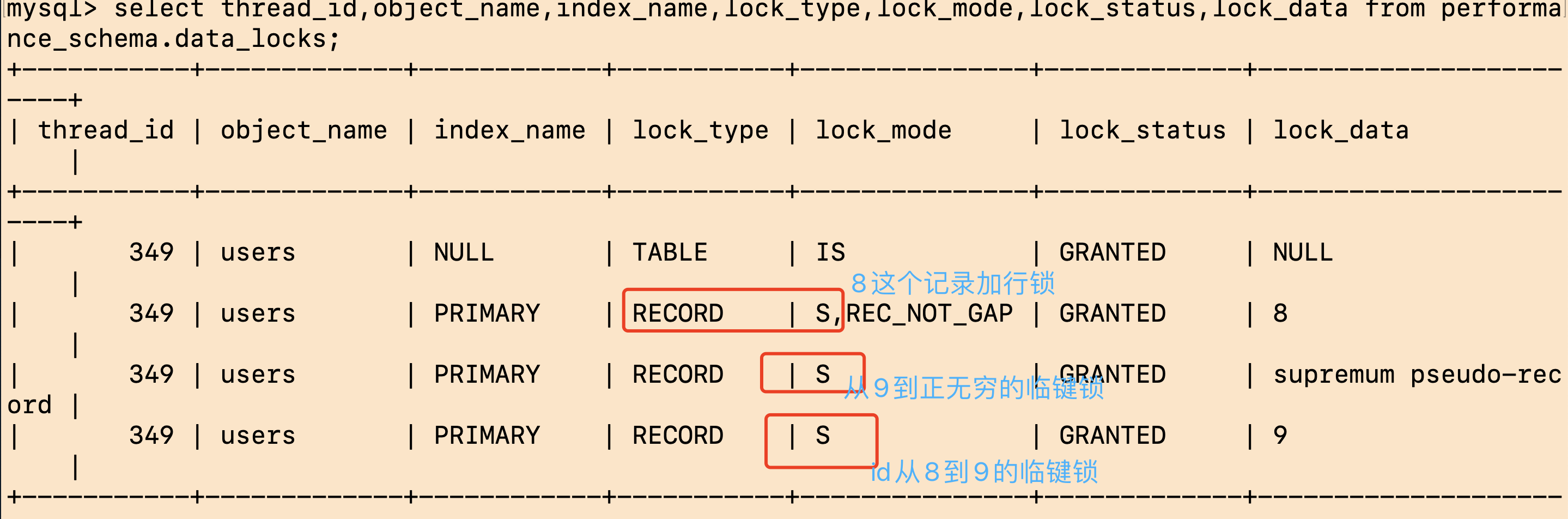
加临键锁,从id=8到正无穷,id=8会被加上行锁
2、rollback会话1,重新开启事务,执行下面语句
-- 手动共享锁
select * from users where id <= 3 lock in share mode;
+----+----------+------+
| id | name | age |
+----+----------+------+
| 1 | zhangsan | 1 |
| 3 | wangwu | 3 |
+----+----------+------+
2 rows in set (0.00 sec)
查看锁情况:

id小于等于3的记录都会加上临键锁,如果有id=2的记录,则id=2也会加上临键锁。
符合原则3
总结
1、行级锁加锁单位为next-key lock临键锁,临键锁由记录和间隙锁组成。
2、间隙锁不互斥,同一个间隙可以多个事务同时加间隙锁。
3、只可能对扫描过的索引加锁,select *也会扫描主键索引。
4、行级锁加锁原则:
1)、唯一索引等值查询,如果存在则临键锁退化为行锁;
2)、唯一索引的等值查询,如果不存在,向右遍历第一个不满足的情况时,优化为间隙锁;
3)、唯一索引的范围查询,访问到不满足条件的第一个值为止,加上临键锁;
4)、普通索引的等值查询,向右遍历时最后一个值不满足查询条件时,最后的next-key lock优化为间隙锁;
5)、如果不通过索引进行检索加锁,那么会对所有记录加锁,相当于表锁了。
5、可以通过对应加锁语句进行查看加锁情况
select thread_id,object_name,index_name,lock_type,lock_mode,lock_status,lock_data from performance_schema.data_locks;