




网络
未读
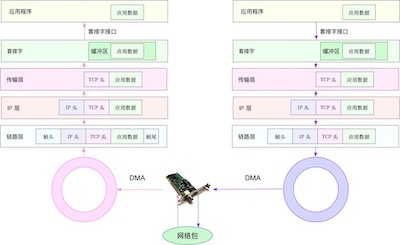
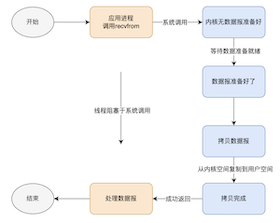
Linux网路包收发流程
文章会先简单介绍网络模型,主要是更为实用的TCP/IP模型;再介绍关于Linux内核网络栈;最后关于底层的网络包收发流程,熟悉底层收发流程对于我们掌握IO模型或者日常开发中涉及网络接口的底层传输会更加清晰和易懂。
随笔
未读
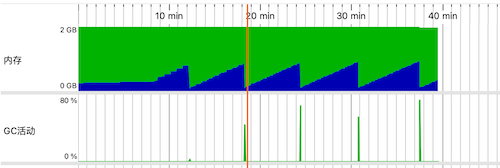
记一次服务内存异常处理
一般生产运行的服务都会有相关的指标监控,方便我们查看服务的健康状态,Grafana+Prometheus是一种常见的方式。本文主要是根据Grafana通过对内存的监控发现内存出现异常(泄漏)进而排查与处理的过程。
mysql
未读
Sql与锁以及容易被忽视的Insert语句
本篇主要介绍InnoDb引擎RR事务隔离级别下的一些锁相关的内容,结合mysql官方文档和一些演示来说明不同执行sql与其加锁的方式,Innodb有哪些类型锁呢,锁类型介绍主要偏概念一些;最后再深入看下insert场景的加锁方式。

mysql
未读
mysql有关data_locks表说明
最近重新看mysql行锁、表锁相关的内容时,发现关于什么情况加锁、加什么锁、什么时候事务阻塞等等有很多的规则,要分析的第一步就是要看锁相关的信息,performance_schema库的data_locks表就提供了相关的信息,借助官方文档系统看下。


ElasticStack
未读
ElasticSearch的分词器
我们都知道,ES的核心功能之一便是全文本搜索,这种全文本搜索,可以返回相关的结果,而非精确的匹配结果。
那么文本分析Analysis发挥了重要的作用,为什么索引一个文本如“My Name is Old Nico”,当搜索“My Nico”时可以搜索的到呢?