Elasticsearch入门篇
前言
Elasticsearch 简称ES,是Java编写的一个开源的分布式搜索和分析引擎,适合大数量复杂查询和高并发场景。
ES提供了近实时的查询和分析能力,不管是结构化还是非结构化文本、数字还是地理数据,它都能高效的存储与索引。
ES在多种场景提供了快速和可扩展的数据查询能力,包括如下:
1、存储并分析日志、指标等场景,支持全文、精确、排序、范围、聚合等查询能力
2、实时分析行为数据
3、可用于管理和分析特殊的地理位置数据
4、可用于生物学领域基因数据的存储、搜索和分析(高级)
概念
集群(cluster)
ES集群有一个或多个Elasticsearch节点组成,每个节点配置相同的 cluster.name 即可加入集群,默认值是”elasticsearch“。
一个Elasticsearch服务实例就是一个节点
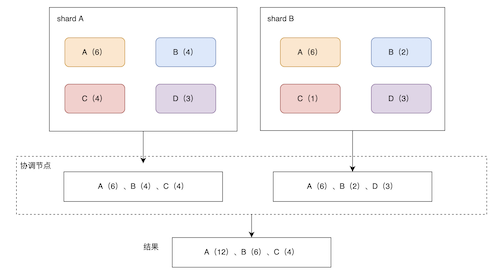
分片(shard)
ES数据在进行索引的时候,会拆分到不同的数据块上,拆分出来的数据块则是一个分片。
分片是ES中最小的工作单元,对应着一个Lucene的index。
分片会在索引创建的时候指定数量,一但指定便不支持修改,在一个多分片的索引写入时,通过路由的方式确定写入哪个分片。
// 创建一个包括5个分片的索引
PUT /indexname
{
"settings" : {
"number_of_shards" : 5
}
}
副本(replicas)
副本是对应分片的一个Copy,用来提高可用性,当主分片异常时,使用副本来提供查询的能力。
同一个索引的主分片和对应副本分片不能在同一个节点上,所以副本最多是N-1,N表示节点数量,例如主分片1个,副本分片3个,当节点是3个的时候,有1个副本分片无法分配,集群变黄。同一个索引不同的主分片可以在同一个节点上。
举例:
有3个数据节点;一个索引设置了两个主分片,一个副本分片,那么3个数据节点的分片如下:【p0,r1】【p1】【r0】
索引(index)
索引时拥有一些相似特征的文档集合,相当于关系型数据库中的数据库,例如一个商品数据的索引,一个订单数据的索引。
需要注意下,索引的名称所有字母必须小写。
类型(type)
在6.x版本前,一个索引允许定义多种类型文档,相当于关系型数据中的表。在6.x后一个索引只允许一个类型,7.x后这个类型限制成只能是_doc。
映射(mapping)
映射表示如何定义一个文档中字段的类型、属性等。每个文档有多个字段,字段有它们自己的数据类型和属性,可以动态映射类型也可以显示指定其类型等。相当于关系型数据库的Schema。
文档(document)
一个文档就是被索引的一个信息基本单元,相当于关系数据库中的一行记录,例如为某一个商品创建文档。文档 可以用JSON格式来进行表示。
字段(field)
字段是组成文档的最小单元,相当于关系型数据库中的某一列数据。
小结:
新版Elasticsearch与关系型数据库的映射关系如下所示:

安装
1、进入官方下载地址,选择对应的平台,点击下载
2、下载后在本地解压缩到某目录path下,进入es目录下,便是 $ES_HOME。
本篇示例版本:elasticsearch-8.6.2
此时可以看到多个文件夹,包括bin、lib、config、data、logs等。
具体的文件夹描述可以参考文档>
3、修改配置
在本机启动演示,关闭掉安全校验,修改配置文件$ES_HOME/config/elasticsearch.yml文件
将xpack.security相关的enabled改成false。
4、进行启动
进入到$ES_HOME目录下,mac/linux下执行命令:./bin/elasticsearch
控制台可以查看到具体的启动日志。
如果出现报错:not all primary shards of [.geoip_databases] index are active
通过增加配置项解决:ingest.geoip.downloader.enabled: false
如果想后台进程启动,可以通过增加-d选项,即执行 ./bin/elasticsearch -d 即可。
5、通过访问:http://localhost:9200,确定启动成功
REST API 使用
官方rest api地址传送门>
添加文档
POST http://localhost:9200/myindex/_doc/1
请求:
{
"name": "John",
"age": 25,
"about": "I love to go rock climbing"
}
返回:
{
"_index": "myindex",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
查询文档
1、条件搜索
GET http://localhost:9200/myindex/_search?q=name:John
返回
{
"took": 66,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "myindex",
"_id": "1",
"_score": 0.2876821,
"_source": {
"name": "John",
"age": 25,
"about": "I love to go rock climbing"
}
}
]
}
}
如果多字段组合查询使用:q=field1:value1 AND field2:value2
2、搜索所有
GET http://localhost:9200/myindex/_search
返回:
{
"took": 40,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "myindex",
"_id": "1",
"_score": 1,
"_source": {
"name": "John",
"age": 25,
"about": "I love to go rock climbing"
}
}
]
}
}
3、更多搜索场景
全文搜(match会进行分词):
POST:http://localhost:9200/myindex/_search
{
"query" : {
"match" : {
"about" : "collect rock climbing"
}
}
}
短语(match_phrase 不会分词):
POST:http://localhost:9200/myindex/_search
{
"query" : {
"match_phrase" : {
"about" : "collect rock climbing"
}
}
}
修改文档
官方地址传送门>
POST:http://localhost:9200/myindex/_update/1
请求:
{
"doc": {
"age":26
}
}
返回:
{
"_index": "myindex",
"_id": "1",
"_version": 3,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1
}
删除文档
官方地址传送门
DELETE http://localhost:9200/myindex/_doc/1
返回:
{
"_index": "myindex",
"_id": "1",
"_version": 4,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 1
}
问答
1、问:ES为什么是近实时的?
答:因为ES索引数据,并不是立马刷新到可见区,为了提高查询和索引性能,默认会在1秒后刷新,即1秒后可被搜索,可通过配置:“refresh_interval”: "1s"进行修改。
总结
ES作为分布式及可扩展的搜索引擎,提供了快速索引和搜索能力,本篇属于入门级文章,多动手,多尝试。