Logstash批量Mysql数据导到Elasticsearch
前言
上一篇了解了ES的初步使用,本篇主要介绍如何将其它数据源的数据同步到ES中,会重点讨论通过Logstash将Mysql导入到ES中。
先来了解下Logstash吧
Logstash是Elastic Stack的一部分,一个开源的数据收集引擎,具有强大的数据收集、处理、传输能力。支持丰富的输入输出插件,可以使用Jdbc插件完成将Mysql数据迁移到ES中。
Logstash支持的输入插件可参考>
安装
1、进入下载地址进行下载,选择对应平台,点击下载
2、下载的文件解压缩到对应目录path下,进入logstash目录下,该目录便是 $LOGSTASH_HOME。
本篇示例版本:logstash-8.6.2
3、进入 $LOGSTASH_HOME 目录,可以看到几个文件夹,包括bin、log、config、data等
具体的目录文件说明可参考>
4、启动时需要指定配置文件,配置文件进行输入输出插件的配置,启动后进行相应的数据传输。
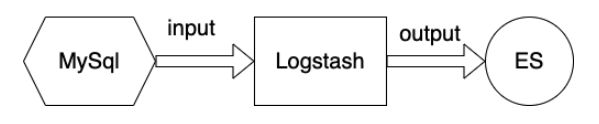
导入数据
流程如下图所示:
初始化表数据
1、定义表结构
CREATE TABLE `user` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`name` varchar(30) DEFAULT NULL COMMENT '姓名',
`age` int DEFAULT NULL COMMENT '年龄'
PRIMARY KEY (`id`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户表';
2、插入初始化数据
insert into user(id, `name`, age)
values(1, 'jack', 18),
(2, 'rock', 20),
(3, 'hock', 21);
配置文件
首先需要配置输入输出插件,配置文件可放于config目录下
input {
jdbc {
jdbc_driver_library => "~/Documents/dev/es/logstash-8.6.2/bin/mysql-connector-java-8.0.20.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/test?characterEncoding=UTF-8&useSSL=false"
jdbc_user => root
jdbc_password =>
jdbc_paging_enabled => "true" #是否进行分页
jdbc_page_size => "2"
tracking_column => "id"
use_column_value => true
clean_run => true
# statement_filepath => "sql文件路径,与下面的执行语句二选1"
statement => "SELECT id,name,age FROM user id WHERE id > :sql_last_value"
# 设置监听间隔 各字段含义(由左至右)秒、分、时、天、月、年,全部为*默认含义为每分钟都更新
schedule => " 10 * * * * *"
}
}
output {
elasticsearch {
document_id => "%{id}"
# document_type => ""
index => "userindex2"
hosts => ["http://localhost:9200"]
}
stdout{
codec => json_lines
}
}
主要包括input和output插件配置。
1、input jdbc相关属性说明
- jdbc_driver_library:指定jdbc驱动包路径
- jdbc_driver_class:定义数据库驱动类
- jdbc_connection_string:配置数据库的连接
- jdbc_user:配置数据库的用户名
- jdbc_password:配置数据库的密码
- jdbc_paging_enabled:配置是否进行分页,如果配置分页,则会先进行count查询,然后按分页大小进行获取数据,默认false
- jdbc_page_size:分页大小,配合jdbc_paging_enabled使用,默认值100000
- tracking_column:用于配置追踪的字段,设置后配合:sql_last_value,每次查询可以从该位置查询
- tracking_column_type:追踪字段的类型,目前仅支持类型支持两种:numeric(默认)、timestamp
- use_column_value:如果设置成true,则使用tracking_column的值作为:sql_last_value;如果设置成false,:sql_last_value则使用最近一次查询的时间,默认false
- clean_run:上一次的执行状态是否被保留,如果设置成true则不会被保留,当use_column_value是true,那么初始时 :sql_last_value则是1970-01-01或者0;如果是false,则上次执行状态保留在属性last_run_metadata_path设置的文件中,默认false
- statement:配置查询sql
- schedule:设置监听间隔,多久进行一次同步,符合cron表达式
更多属性说明参考>
2、output相关属性说明
elasticsearch相关属性:
- document_id:es中存储的文档id
- index:es中存储的索引名称(注意es中索引名称字母的话必须小写)
- hosts:配置es的域名和端口
stdout相关属性:
用于配置标准输出,方便进行Debug,数据进行处理和过滤时可以打印日志,codec包括两种,rubydebug和json
执行
配置完成执行,进入 $LOGSTASH_HOME 目录
执行:./bin/logstash -f config/my-demo-logstash.conf
-- 部分日志如下:
[2023-05-20T09:51:10,717][INFO ][logstash.inputs.jdbc ][main][a5d1e2414385afacea929789902493118eab9c05a565554e75462e93425330a0] (0.060362s) SELECT version()
[2023-05-20T09:51:10,738][INFO ][logstash.inputs.jdbc ][main][a5d1e2414385afacea929789902493118eab9c05a565554e75462e93425330a0] (0.000747s) SELECT version()
[2023-05-20T09:51:10,763][INFO ][logstash.inputs.jdbc ][main][a5d1e2414385afacea929789902493118eab9c05a565554e75462e93425330a0] (0.010282s) SELECT count(*) AS `count` FROM (SELECT id,name,age FROM user id WHERE id > 0) AS `t1` LIMIT 1
[2023-05-20T09:51:10,770][INFO ][logstash.inputs.jdbc ][main][a5d1e2414385afacea929789902493118eab9c05a565554e75462e93425330a0] (0.000835s) SELECT * FROM (SELECT id,name,age FROM user id WHERE id > 0) AS `t1` LIMIT 2 OFFSET 0
[2023-05-20T09:51:10,782][INFO ][logstash.inputs.jdbc ][main][a5d1e2414385afacea929789902493118eab9c05a565554e75462e93425330a0] (0.000938s) SELECT * FROM (SELECT id,name,age FROM user id WHERE id > 0) AS `t1` LIMIT 2 OFFSET 2
/Users/xudj/Documents/dev/es/logstash-8.6.2/vendor/bundle/jruby/2.6.0/gems/manticore-0.9.1-java/lib/manticore/client.rb:284: warning: already initialized constant Manticore::Client::HttpPost
/Users/xudj/Documents/dev/es/logstash-8.6.2/vendor/bundle/jruby/2.6.0/gems/manticore-0.9.1-java/lib/manticore/client.rb:284: warning: already initialized constant Manticore::Client::HttpPost
{"@timestamp":"2023-05-20T01:51:10.780010Z","age":20,"@version":"1","name":"rock","id":2}
{"@timestamp":"2023-05-20T01:51:10.784010Z","age":21,"@version":"1","name":"hock","id":3}
{"@timestamp":"2023-05-20T01:51:10.778956Z","age":18,"@version":"1","name":"jack","id":1}
配置了调度任务schedule
schedule => " 10 * * * * *" 表示每分钟的第10秒进行任务调度
如果没有配置schedule,初始化处理完成则结束。
[2023-05-20T09:52:10,620][INFO ][logstash.inputs.jdbc ][main][a5d1e2414385afacea929789902493118eab9c05a565554e75462e93425330a0] (0.007535s) SELECT count(*) AS `count` FROM (SELECT id,name,age FROM user id WHERE id > 3) AS `t1` LIMIT 1
执行完成后,通过es查看输入的索引数据:
GET:http://127.0.0.1:9200/userindex2/_search
能查到数据则表明数据传输成功。
问题
问题1 报错未知命令
执行Logstash 命令时没有使用 -f 参数指定配置文件,Logstash 会认为您指定的配置文件路径是要进行的操作或输入,从而报错未知命令。
解决:
执行命令加上 -f 指定配置文件即可。
问题2 报错ClassCastException
[ERROR][logstash.inputs.jdbc ][main]
java.sql.SQLException: java.lang.ClassCastException: class java.math.BigInteger cannot be cast to class java.lang.Long (java.math.BigInteger and java.lang.Long are in module java.base of loader 'bootstrap')
低版本不兼容导致。
解决:
jbdc驱动包升级到8 版本(mysql-connector-java-8.0.20.jar)
问题3 使用分页报错
配置了
jdbc_paging_enabled => “true” #是否进行分页
同时执行了分页大小。
在测试tracking_column为时间时,报错:
Exception when executing JDBC query {:exception=>Sequel::DatabaseError, :message=>"Java::JavaSql::SQLException: [161ca41c0b002000]
[10.40.26.240:3015][pbc_price_pre]syntax error, error in :'where create_time > '1970-01-01 00:0', expect ), actual ;, pos 415, line 3, column 86, token ;",
:cause=>"#<Java::JavaSql::SQLException: [161ca41c0b002000][10.40.26.240:3015][pbc_price_pre]syntax error, error in :'where create_time > '1970-01-01 00:0', expect ), actual ;, pos 415, line 3, column 86, token ;>"}
根据:SELECT count(*) AS count FROM (SELECT * FROM table id WHERE id > 0;) AS t1 LIMIT 1;得知,statement配置sql语句时多了个;符号,所以查询数量时报错。
解决:
1、去掉sql最后的英文分号
2、不使用分页配置。
问题4 tracking_column配置失败
tracking_column not found in dataset. {:tracking_column=>"create_time"}
如果sql语句中重新定义了column,tracking_column配置的字段不认识原sql的字段名。
解决:
tracking_column需要填写定义的列名称
另外,logstash默认会把列名转小写,需要配置lowercase_column_names => “false” 方可支持保留大写。
问题5 索引名称错误
"error"=>{"type"=>"invalid_index_name_exception", "reason"=>"Invalid index name [userIndex2], must be lowercase"
output.elasticsearch.index
解决:
索引名称不支持大写字母,需要改成小写。
总结
Logstash支持了非常多的输入输出插件,进行配置即可。
Jdbc输入插件将数据库数据导入ES,目前是通过主动调度任务进行配置,以一种主动拉取的方式进行的,最快支持每秒拉取(调度配置:* * … 或 */1 *…)。
如果不配置调度任务,则初始化完成变会结束,不进行增量的同步。
如果想通过数据库binlog做到实时同步,可以参考中间件Canal、一些云产品DTS等。